
What does o3 mean? The "scaling law" continues in 2025, with costs becoming more expensive and less controllable

Anthropic 聯合創始人 Jack Clark 認為明年,AI 界將結合 “測試時擴展” 和傳統的預訓練擴展方法,進一步挖掘 AI 模型的潛力。不過,雖然 o3 模型讓人們重新相信 AI 擴展法則的進展,但是,o3 使用了前所未見的計算量,這意味着每個答案的成本更高了,也意味着 o3 可能無法成為人們的日常使用工具。
AI 擴展法則進入第二代,當然,成本也是如此。
近期,AI 發展似乎進入了 “第二個擴展法則時代(Second era of Scaling Laws)”,一些分析師指出,改進 AI 模型的既定方法正在呈現出收益遞減的趨勢,目前,一種新的、有前景的方法是 “測試時擴展( test-time scaling)”,這是 OpenAI 的 o3 模型採用的方法,也是 o3 表現如此出眾的原因。
需要注意的是,儘管 o3 模型讓人們重新相信 AI 擴展法則的進展,但也並非十全十美:o3 使用了前所未見的計算量,這意味着每個答案的成本更高了,也意味着 o3 無法成為人們的日常使用工具。
具體來説,“測試時擴展” 意味着 OpenAI 在 ChatGPT 的推理階段使用了更多的計算資源——在用户按下生成按鈕後到 AI 給出答案之間的那段時間,OpenAI 可能是在使用更多的計算芯片來回答用户的問題,也可能是在使用更強大的推理芯片,甚至可能是更長時間地運行這些芯片,畢竟,在某些情況下,o3 在 10 到 15 分鐘後才給出答案。
此外,Anthropic 聯合創始人 Jack Clark 和另一些分析師指出,o3 在 ARC-AGI 基準測試中的出色表現標誌着 AI 模型的進步,但是,通過這一測試並不意味着 AI 模型已經達到了通用人工智能(AGI),畢竟,o3 在一些非常簡單的任務上仍然失敗了,而這些任務人類可以輕鬆完成——顯然,o3 和 “測試時擴展” 仍未解決大語言模型的幻覺問題。
AI 在 2025 年的進步將比 2024 年更快,o3 就是證據
Clark 在週一的博客中表示,o3 模型表明,基於目前已有強大基礎模型,在推理時讓大語言模型 “測試時擴展”,能夠帶來巨大的回報。Clark 預計,接下來最有可能發生的事情是,強化學習(RL)和底層基礎模型將同時得到擴展,這將帶來更加戲劇性的性能提升。
“這是一個大新聞,因為它表明,相較於 2024 年,2025 年 AI 的進展應該會進一步加速。”
Clark 補充表示,最近有很多奇怪的報道,説 “擴展已經遇到瓶頸”,對此,Clark 反駁稱:
“從狹義上講,這是對的,因為較大的模型在應對挑戰性基準時,獲得的得分提升比其前代模型要小,但從更廣義上講,這種説法是錯誤的,因為 o3 背後的技術意味着擴展仍在繼續……到 2025 年,我們將看到現有方法(大模型擴展)和新方法(基於 RL 的 “測試時擴展” 等)的結合。”
Clark 還補充道,明年,AI 界將結合 “測試時擴展” 和傳統的預訓練擴展方法,進一步挖掘 AI 模型的潛力。
表現出眾的 o3
許多人將 OpenAI 發佈的 o3 模型視為 AI 擴展進程沒有 “夭折” 的證明——o3 在基準測試中表現出色,在一項名為 ARC-AGI 的通用能力測試中,它的得分遠遠超過所有其他模型,某次嘗試中得分甚至達到了 88%,而 o1 的最好表現僅為 32%。並且,o3 在一項困難的數學測試中達到了 25% 的得分,沒有任何其他 AI 模型的得分超過 2%。
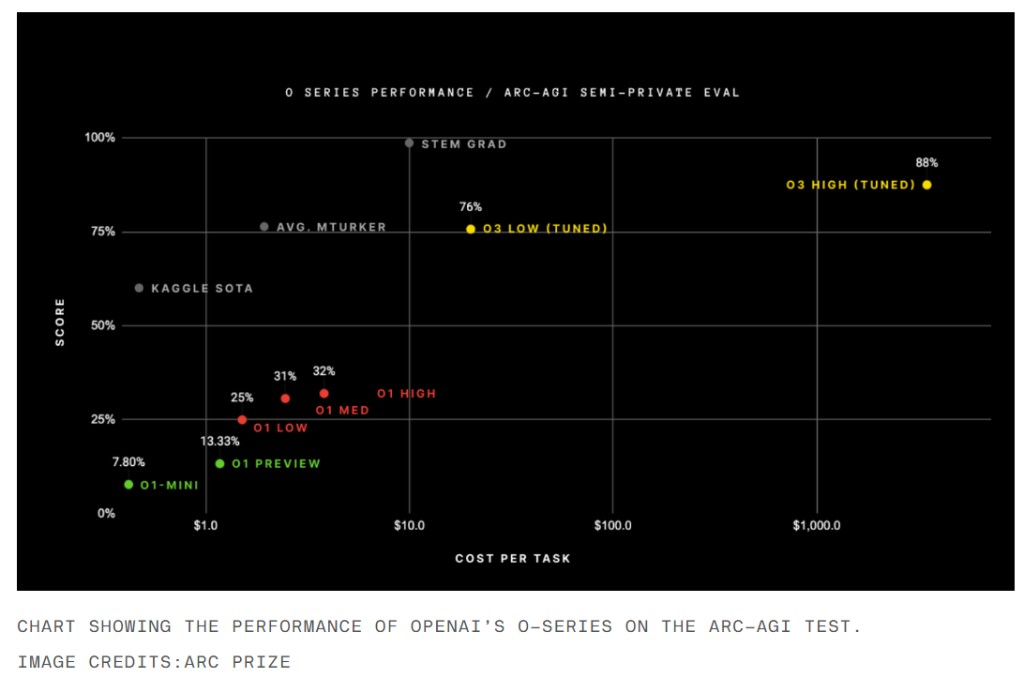
o 系列模型的共同創造者 Noam Brown 在上週五表示,OpenAI 在宣佈 o1 模型後的僅僅三個月就發佈了 o3 模型,AI 性能的進步速度令人印象深刻:
“我們有充分的理由相信,這一發展軌跡將繼續下去。”
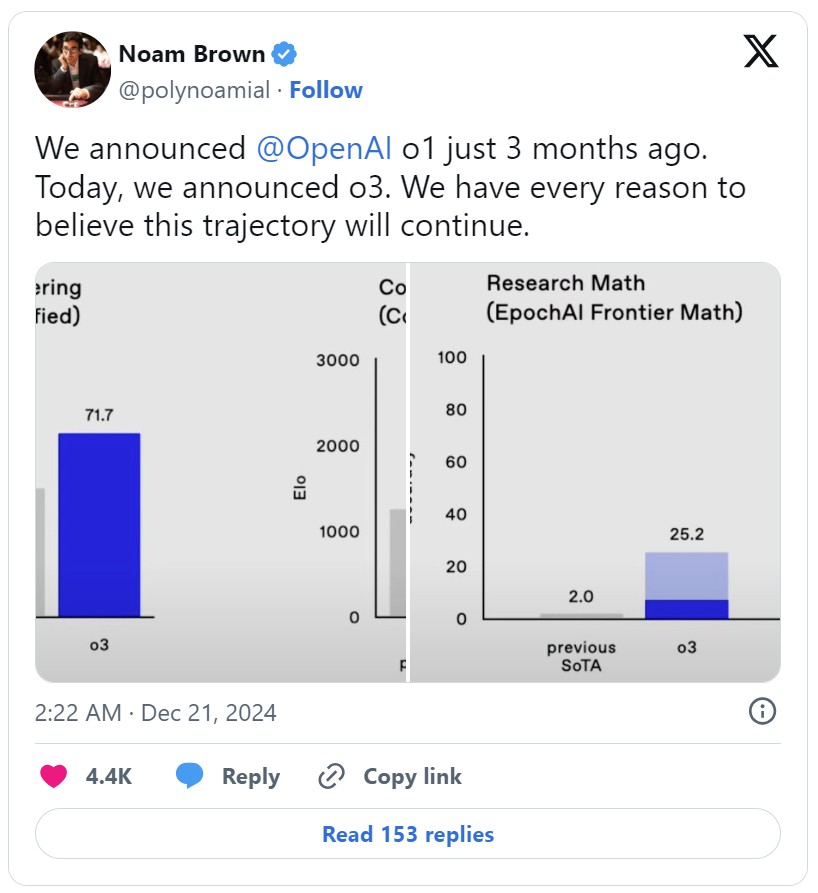
價格昂貴的 o3
儘管 o3 模型讓人們重新相信 AI 擴展法則的進展,但也並非十全十美:o3 使用了前所未見的計算量,這意味着每個答案的成本更高了。
Clark 在博客中寫道:
“或許唯一需要注意的點是,o3 之所以表現得更好,部分原因在於它在推理時的運行成本更高——能夠利用 “測試時擴展” 意味着在某些問題上,你可以通過增加計算資源得到更好的答案。這很有意思,因為它使得運行 AI 系統的成本變得更加難以預測——之前,你只需通過查看模型本身以及生成某個輸出的成本,就能估算出運行生成模型的費用。”
再一次回到這張圖,除了 o3 在縱座標上獲得的極高得分,o3 在橫座標上也一騎絕塵——o3 的高得分版本在每個任務上使用了超過 1000 美元的計算資源,而 o1 在每個任務上僅僅使用了約 5 美元的計算資源,o1-mini 在每個任務上只用了幾美分。
ARC-AGI 基準測試的創造者 Francois Chollet 在博客中寫道:
“OpenAI 為了生成 88% 的得分,使用了比 o3 高效版本多出約 170 倍的計算資源,而高效版本的得分僅比高得分版本低 12%。”
Chollet 繼續補充道:
“o3 是一個能夠適應之前從未遇到的任務的系統,可以説在 ARC-AGI 領域的表現已經接近了人類的水平,當然,這種通用性的代價很高,且目前還不具備經濟效益。”
不過,現在討論具體定價還為時尚早了,畢竟,AI 模型的價格在過去一年中大幅下跌,OpenAI 也尚未宣佈 o3 的實際費用。更值得探究的是,o3 高昂計算價格顯示出,突破當前領先 AI 模型的性能門檻,到底需要多大的計算量。
仍有侷限的 o3
雖然 o3 在各類測試中表現出色,但它確實不是十全十美的。
分析師指出,o3 或其後繼模型不會成為像 GPT-4 或谷歌搜索這樣的 “日常使用工具”,因為這些模型使用了過多的計算資源,無法回答日常的小問題,比如 “克里夫蘭布朗隊怎麼才能有機會進入 2024 年季後賽”。
是的,使用了 “擴展測試時計算” 的 AI 模型可能僅適用於更宏觀的問題,比如 “克里夫蘭布朗隊如何在 2027 年成為超級碗冠軍隊”。但是,只有當你是克里夫蘭布朗隊的總經理時,使用這些工具來做出重大決策,可能才值得你付出如此高昂的計算成本。
正如沃頓商學院教授 Ethan Mollick 在指出的那樣,只有財力雄厚的機構才有可能負擔得起 o3,至少在初期是這樣。
目前,OpenAI 發佈了一個 200 美元的訂閲層級,供用户使用高計算版本的 o1,但根據報道,OpenAI 最近還在考慮推出價格為 2000 美元的訂閲層級——看到 o3 使用的計算資源後,可以理解為什麼 OpenAI 會如此考慮了。
此外,雖然 o3 在 ARC-AGI 基準測試中的出色表現標誌着 AI 模型的進步,但是,通過這一測試並不意味着 AI 模型已經達到了通用人工智能(AGI),畢竟,o3 在一些非常簡單的任務上仍然失敗了,而這些任務人類可以輕鬆完成——顯然,o3 和 “測試時擴展” 仍未解決大語言模型的幻覺問題。
