
The AI model layer may be completely unprofitable
The monetization opportunities at the AI model layer are limited and may yield no profits. The a16z podcast mentioned that the AI large model layer is not a good monetization layer, similar to the commoditization process of IT technology. Historically, IT technology has gradually become a general commodity, and AI is developing in this direction. CEOs of major companies are discussing AI commoditization, and the emergence of DeepSeek makes it possible to deploy AI on more devices, with service providers beginning to compete on cost
I listened to a16z's podcast over the weekend, and it was very enlightening; there was a statement about the monetization of large models that left a deep impression on me:
That (LLM model layer) is not the best layer to monetize it. In fact, there might not be any money in that layer.
The general idea is that at the level of AI large models, the opportunities for monetization are not very significant; in fact, at the level of AI models, there is no profit to speak of.
Following some thoughts mentioned in the podcast, let's discuss the profit of the AI model layer vs. the marginal cost of AI applications.
The AI model layer is not a good monetization layer
1/ Is the AI model a "generic commodity"? This debate is not new; however, now, DeepSeek has pushed this narrative to another level. Let's review some key milestones:
-
2003 - Nicholas Carr's article "IT Doesn't Matter"; perfectly explained how IT technology became a "generic commodity" and ultimately became "irrelevant";
-
2022 - chatGPT emerged; began to hear sporadic thoughts about the commoditization of IT extending to AI;
-
May 2023 - Google's internal documents claimed that AI does not have a moat;
-
2024 - CEOs of major companies publicly discussed AI commoditization; for example, Microsoft and Amazon (especially at the re:invent conference);
-
January 2025 - DeepSeek emerged; deploying AI on smaller and more devices became possible; many service providers have begun to compete to offer the lowest-priced R1 solutions (starting to compete from a "cost perspective");
-
February 2025 - OpenAI began discussing open source;
2/ If you accept that AI models will ultimately become "generic commodity" technology, and there is no obvious "differentiation" / "network effects," then it becomes very difficult to establish a business model with significant premiums / profits based on this. At this level, you can basically only discuss "marginal costs";
3/ This statement still feels somewhat counterintuitive at this point in time. The giants have used the largest capital on Earth to purchase a large number of the most advanced NVIDIA chips, isn't it to create the most complex "AI pearls"? How did it become a "generic commodity"?
4/ A technology being complex and sophisticated does not mean it cannot become a "generic commodity." To give a not-so-apt example, personal computers seem commonplace now, but when they were first invented, they still embodied the most advanced hardware and software of the time; this does not mean they cannot gradually iterate and become a "generic commodity." Even the lowest-end smartphones today would have been considered very complex ten years ago, yet they can only be sold based on "marginal cost"; (Apple has captured most of the profits in the smartphone market precisely because it has turned itself into a consumer discretionary company, rather than just a tech company.)
5/ History has also provided some insights. Looking back at the history of the internet, people once overly focused on monetizing the foundational infrastructure of the internet (i.e., HTML and HTTP), but history has ultimately proven that the commercial value of the internet lies not in the underlying protocols, but in the application layer (such as the e-commerce/advertising/streaming services we are familiar with today);
If the example of HTTP seems too outdated, one can also refer to the investment experience during the "5G era"; at that time, a large number of fund managers rushed into 5G infrastructure targets like China Mobile, but it ultimately proved that application companies like Tencent captured most of the industry's profits.
6/ Amazon provided some good descriptions of the commercialization of AI models during its Re:Invent event last December, which still offer many insights today; the gist is that AI capabilities will become extremely important, so important that they will no longer be considered something very special (steel is essential for constructing modern buildings, but steel is also just a commodity; whoever is cheaper and more useful will be the one used.)
AI models are no longer special but have become one of the computational processes needed to build AI applications, just like databases and storage in the era of cloud computing.
7/ Returning to the moat of large AI models, Google's internal documents from 2023 have actually "predicted" the emergence of challengers like DeepSeek; here are some excerpts:

-
We have been closely monitoring OpenAI; who will cross the next milestone? What will the next step be? But the uncomfortable truth is that we are not prepared to win this arms race, and neither is OpenAI. While we argue, a third party (open-source models) is quietly taking away our market.
-
Simply put, open-source models are surpassing us; for example, people are running basic models on Pixel 6 phones at 5 tokens per second; people can also fine-tune personalized AI on their laptops overnight;
-
Although our models still have a slight edge in quality, the gap is closing astonishingly fast. Open-source models are faster, more customizable, better in privacy, and more cost-effective in capability. They accomplish what we struggle to do with $10 million and 540 billion parameters using just $100 and 13 billion parameters. Moreover, they achieve this in weeks, not months This has a profound impact on us;
-
We have no secret weapon. Our best hope is to learn from and collaborate with others outside of Google. We should prioritize supporting third-party integrations; people will not pay for a limited model when free, unrestricted alternatives are comparable in quality. We should consider where our true value lies.
-
Giant models are slowing down our progress. In the long run, the best models are those that can iterate quickly. Since we know what can be achieved in the <20B parameter range, we should view small variants as significant rather than an afterthought.
-
We should seriously consider whether each new application or idea really requires an entirely new model. If we do have significant architectural improvements that prevent direct reuse of model weights, then we should invest in more aggressive distillation forms to retain the capabilities of the previous generation as much as possible.
-
If we can iterate on small models more quickly, large models will not necessarily be more capable in the long run; the production cost of LoRA updates is very low (around $100), suitable for the most popular model sizes. This means that almost anyone with an idea can generate and distribute one. Training time is typically within a day.
At this speed, the cumulative effect of all this fine-tuning will soon overcome the initial scale disadvantages. In fact, in terms of engineer work hours, the improvement speed of these models far exceeds what we can achieve with the largest variants, and the best models are largely indistinguishable from ChatGPT. Focusing on maintaining some of the largest models on Earth actually puts us at a disadvantage.
- Competing directly with open source is a failed proposition; there is a reason why the modern internet relies on open source. Open source has some important advantages that we cannot replicate.
If the AI model layer cannot be monetized, why are the giants still spending "wasteful money"?
Let’s accept for now that AI large models are about to become "commodities," and that monetization is difficult; then why do the giants continue to increase their capex investments after DeepSeek?
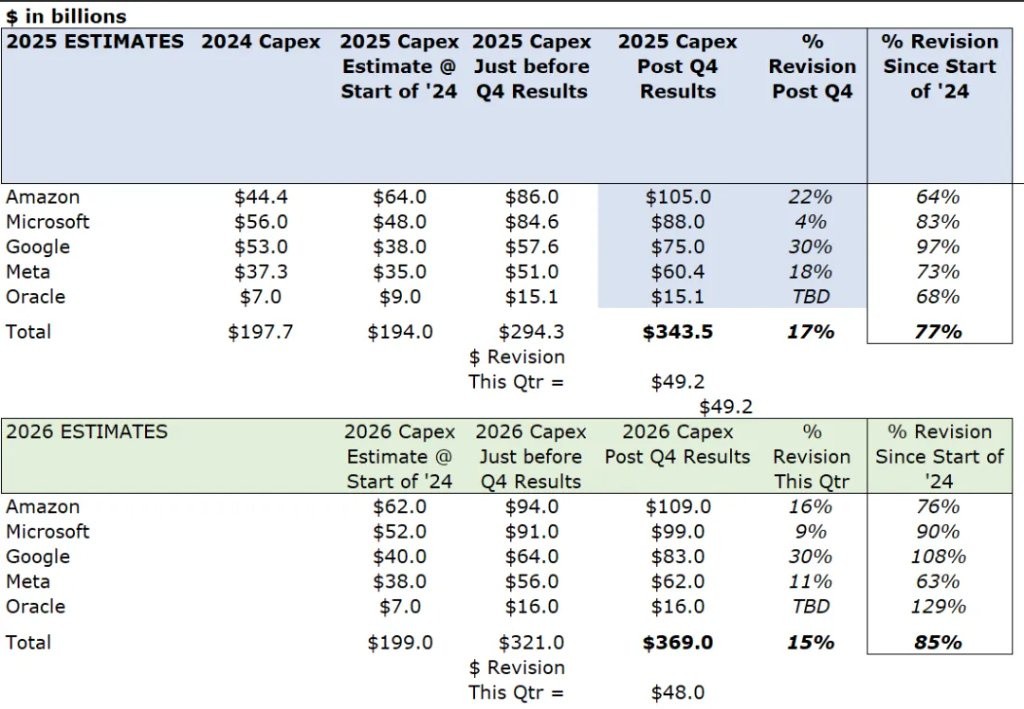
1/ Spending big money to accomplish big things is the thinking inertia of cloud computing giants; currently, most mainstream AI models are driven by cloud vendors (let's set Meta aside for now and discuss it later); during the cloud computing era, they gained competitive advantages through massive capital expenditures, so this thinking inertia naturally carries over into the AI era; in the eyes of the giants, capital expenditure + data is their strategic advantage; thus, scaling up through strategic advantages is a natural progression.
2/ Other Silicon Valley startups also adopt the scale-up approach of large cloud vendors (including Meta + xAI + Anthropic), because within the same ecosystem, everyone is accustomed to optimizing and improving at the micro level, competing for similar resources (talent + computing power + data), while neglecting some macro-level changes in model architecture The Chinese model ecosystem, due to chip limitations, has instead seen breakthroughs like DeepSeek.
3/ This type of cognitive inertia also appeared in the early stages of the internet. Quoting a statement from Marc Andreessen,
During the nascent stage of the internet in the 1990s, many large institutional investors (such as banks or sovereign funds) were eager to invest in the internet but were at a loss on how to invest in software companies; what did these institutions ultimately do? They collectively flocked to invest in fiber optic infrastructure; today we are witnessing history repeat itself: numerous banks and large investors are turning to data center construction because they still struggle to invest in startups. This may lead to a result: just as there was an oversupply of fiber optics back then, we may face a wave of over-construction of data centers.
4/ The massive investments from cloud providers stem from cognitive inertia and FOMO (fear of missing out on this arms race); this is an old topic, so I’ll casually post two images (Google and Meta's statements about FOMO);


5/ Simply put in layman's terms,
-
Big tech is left with nothing but money, having accumulated over a decade of balance sheets, and needs to find a way to spend it (they have been criticized by analysts for spending slowly in previous years);
-
If they still don't know what to invest in, the simplest and most straightforward option is to invest directly in infrastructure; having infrastructure can also attract the corresponding talent (for example, having a KPI of the number of engineers per GPU);
-
FOMO, everyone else is investing, investing doesn't guarantee winning, not investing guarantees losing; "ecological positioning" is crucial for the giants.
-
Capex does indeed have a boosting effect on core business (for example, cloud computing vs recommendation algorithms).
-
Exploring unknown business models; if they really wait until a true business model emerges to catch up, it may be too late.
6/ Specifically regarding each major company,
-
Amazon / Microsoft / Google are all competing for cloud computing market share, regardless of whether their own models can make money, cloud computing is still very profitable; each cloud provider mentioned in this earnings call that if it weren't for capex limitations, cloud computing growth could be even faster.
-
Although Meta does not have its own cloud computing business, the recommendation algorithms for each app and advertising require a massive amount of computing power; even if the models are not usable, the recommendation algorithms can still provide a safety net; Meta is also still resentful about being constrained by Apple during the mobile internet era, so it is even more motivated to position itself in the ecosystem while pursuing the next computing platform (including VR) through open source
-
Here, Apple also has its own "inertia thinking," which is to act as an entry point in the mobile internet era; it only needs to cooperate with the winners of AI models to have a strategic perspective.
Using first principles to deduce Apple's AI strategy
7/ It is worth noting that the excessive investment in fiber optics led to company bankruptcies, which is fundamentally different from the current AI capital investment; this time, the main investors in AI are several major giants, each with very robust core businesses providing almost unlimited funding. Even if the monetization of AI models never arrives, they can remain unscathed; although many people like to compare AI with the internet bubble, the capital back then was mainly venture capital funds; VC money easily faces pressure from later LPs, and their risk tolerance is simply incomparable to these giants.
8/ The inability of AI model layers to make money is not necessarily related to the continuous investment by giants, because the starting point for giants is not entirely from a short-term financial perspective (this involves a lot of game theory). The secondary market has seen that DeepSeek has not led to a significant reduction in Capex spending, and has become excited again, as if nothing has happened. However, this may just be finding the "correct" result through the wrong reasons.
9/ The inability of AI model layers to make money does not mean that giants with advantages in model layers cannot make money through other businesses. For example, although Chrome is free, Google Search captures traffic at the entry point and makes a fortune; the monetization methods from the internet era, such as bundle vs debundle, may still apply.
From the Internet Era to the AI Era
1/ Monetization in the internet era was very simple, "launch free, go viral, work out revenue later"; first, drive up traffic, and then monetization can happen naturally. Monetization in the AI era, at present, does not seem so intuitive.
2/ Tech giants have also attempted to monetize AI; Microsoft's Copilot and Google's Gemini have both made some preliminary attempts at monetization; however, this process has not been smooth, so they have adjusted their billing methods several times; mainly through "bundling with existing businesses" vs "usage-based billing";
Google Gemini

Microsoft Copilot
 3/ The usage-based billing model now seems quite intuitive, as the "reasoning cost" of the AI era has restored software to having "marginal costs"; however, the usage-based billing model is actually quite counterintuitive and goes against the history of computing.
3/ The usage-based billing model now seems quite intuitive, as the "reasoning cost" of the AI era has restored software to having "marginal costs"; however, the usage-based billing model is actually quite counterintuitive and goes against the history of computing.
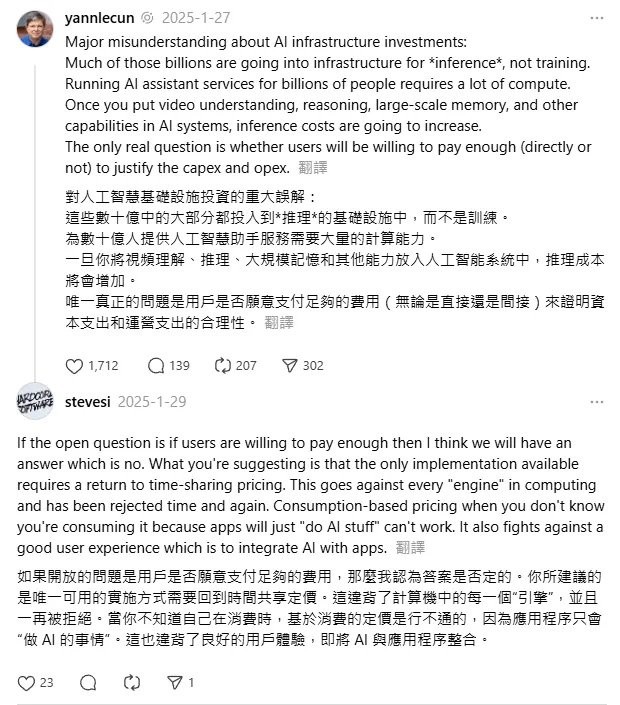
4/ We once experienced the era of "dial-up internet," when data usage was billed based on consumption. I once accidentally spent hundreds of dollars on data fees for downloading a game. However, now, although we pay a monthly internet fee to mobile telecoms, very few people calculate their "internet data usage" anymore.
When internet giants were billing based on data usage, they did not become behemoths; rather, it was when "data was unlimited" (or when there were minimal marginal costs) that they began to consume everything. Another example is that we have never considered how much cloud computing power Taobao needs to mobilize to support each transaction during the Double 11 discount rush.
5/ We are still in the "usage-based billing" phase, possibly because we are still in the "transition period" of this technology application; when we can invoke AI and models as simply as breathing, without ever considering the cost, that may be when the era of AI applications truly arrives.

6/ The emergence of DeepSeek has given us greater hope for the reduction of marginal costs. Here I quote Steven Sinofsky's statement,
The cost of artificial intelligence, much like the cost issues when large computers transitioned to X.25 network connections, essentially forces the market to develop an alternative solution that can scale without large-scale direct capital investment. From all perspectives, DeepSeek's latest solution seems to represent this direction.
DeepSeek's model can run on ordinary commercial hardware and in environments without internet connectivity, and its open-source nature is sufficient to pose a strong challenge to the current path of AI development that relies on massive investments—this breakthrough can be seen as "the direction of future technological evolution."
7/ Yishan has also made similar descriptions about DeepSeek,

8/ Of course, some believe that marginal costs will always exist due to test-time computation; this mainly depends on which stage of technological advancement you believe we are in (test-time computation may ultimately become very cheap) 180k, Original title: "AI Model Layer May Have No Profit (February 10)"
Risk Warning and Disclaimer
The market has risks, and investment requires caution. This article does not constitute personal investment advice and does not take into account the specific investment goals, financial situation, or needs of individual users. Users should consider whether any opinions, views, or conclusions in this article are suitable for their specific circumstances. Investment based on this is at one's own risk
