
Alibaba open-sources the new Qwen3 model, dominating text representation

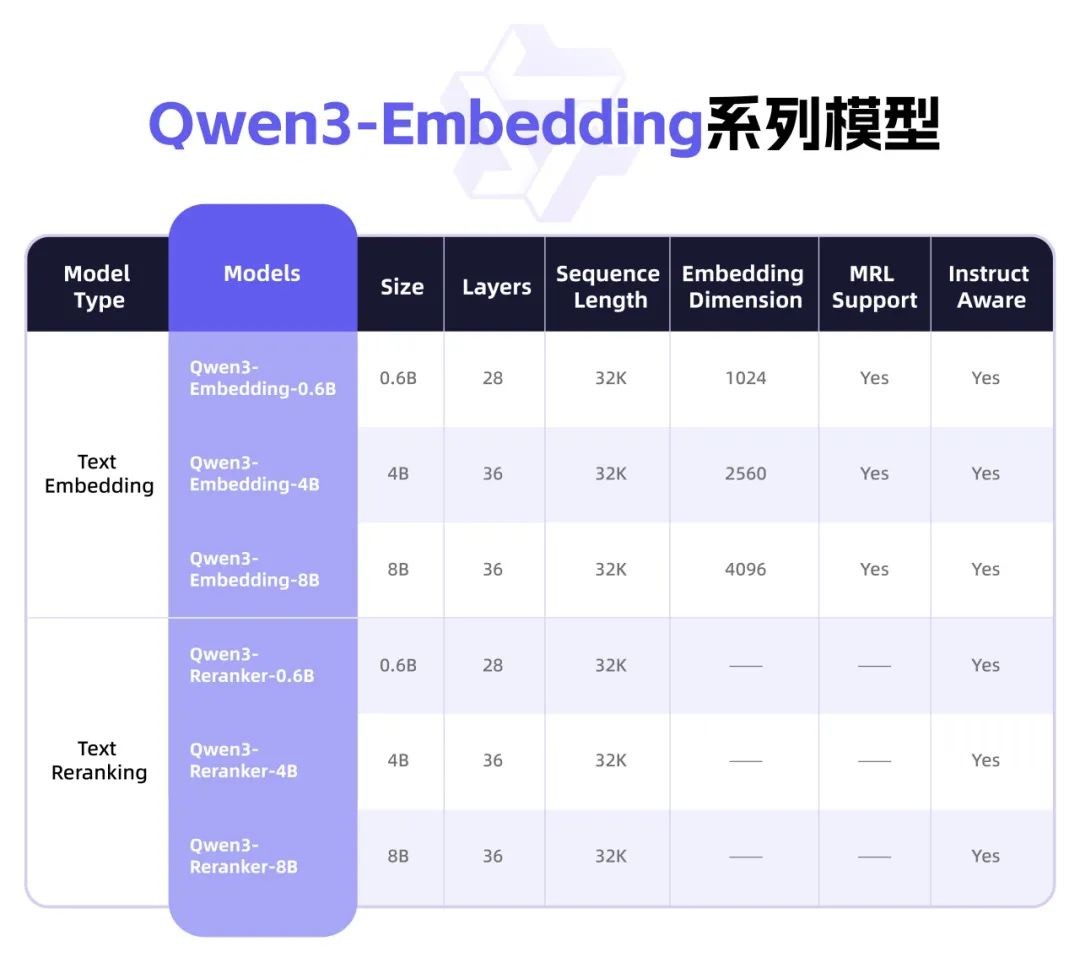
Alibaba has open-sourced the Qwen3 series of new models, including Qwen3-Embedding and Qwen3-Reranker, focusing on text representation, retrieval, and ranking tasks. Qwen3-Embedding performed excellently in multilingual text representation benchmarks, with the 8B parameter model ranking first with a score of 70.58, surpassing Google's Gemini-Embedding. This series supports 119 languages, offering flexible model architectures and customization features, significantly enhancing the relevance of search results
According to Zhitong Finance APP, early this morning, Alibaba (09988) open-sourced two new models from the Qwen3 series, Qwen3-Embedding and Qwen3-Reranker. These two models are specifically designed for text representation, retrieval, and ranking tasks, trained based on the Qwen3 foundational model, fully inheriting Qwen3's advantages in multilingual text understanding, supporting 119 languages. According to test data, Qwen3 Embedding performed exceptionally well in multilingual text representation benchmark tests. Among them, the 8B parameter model ranked first with a high score of 70.58, surpassing many commercial API services, such as Google's Gemini-Embedding.
Outstanding Generalization: The Qwen3-Embedding series achieved industry-leading levels in evaluations across multiple downstream tasks. Among them, the 8B parameter scale embedding model ranked first in the MTEB multilingual leaderboard (as of June 6, 2025, with a score of 70.58), outperforming many commercial API services. Additionally, the ranking model in this series performed excellently in various text retrieval scenarios, significantly enhancing the relevance of search results.
Flexible Model Architecture: The Qwen3-Embedding series offers three model configurations ranging from 0.6B to 8B parameters to meet performance and efficiency needs in different scenarios. Developers can flexibly combine representation and ranking modules to achieve functional expansion.
Furthermore, the model supports the following customization features:
-
Customizable Representation Dimensions: Allows users to adjust representation dimensions according to actual needs, effectively reducing application costs;
-
Instruction Adaptation Optimization: Supports users in customizing instruction templates to enhance performance in specific tasks, languages, or scenarios.
Comprehensive Multilingual Support: The Qwen3-Embedding series supports over 100 languages, covering mainstream natural languages and various programming languages. This series of models possesses strong multilingual, cross-language, and code retrieval capabilities, effectively addressing data processing needs in multilingual scenarios.
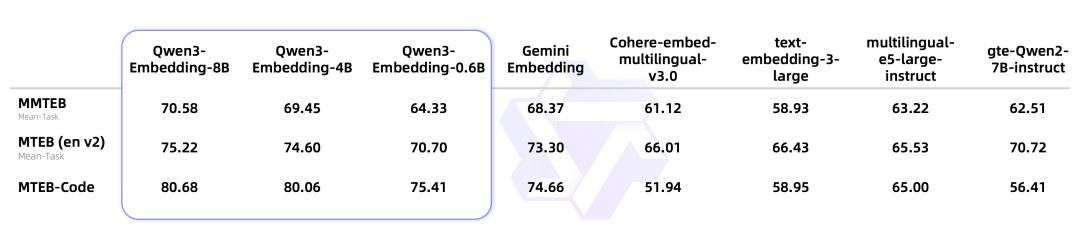
In multiple benchmark tests, the Qwen3-Embedding series demonstrated outstanding performance in text representation and ranking tasks.
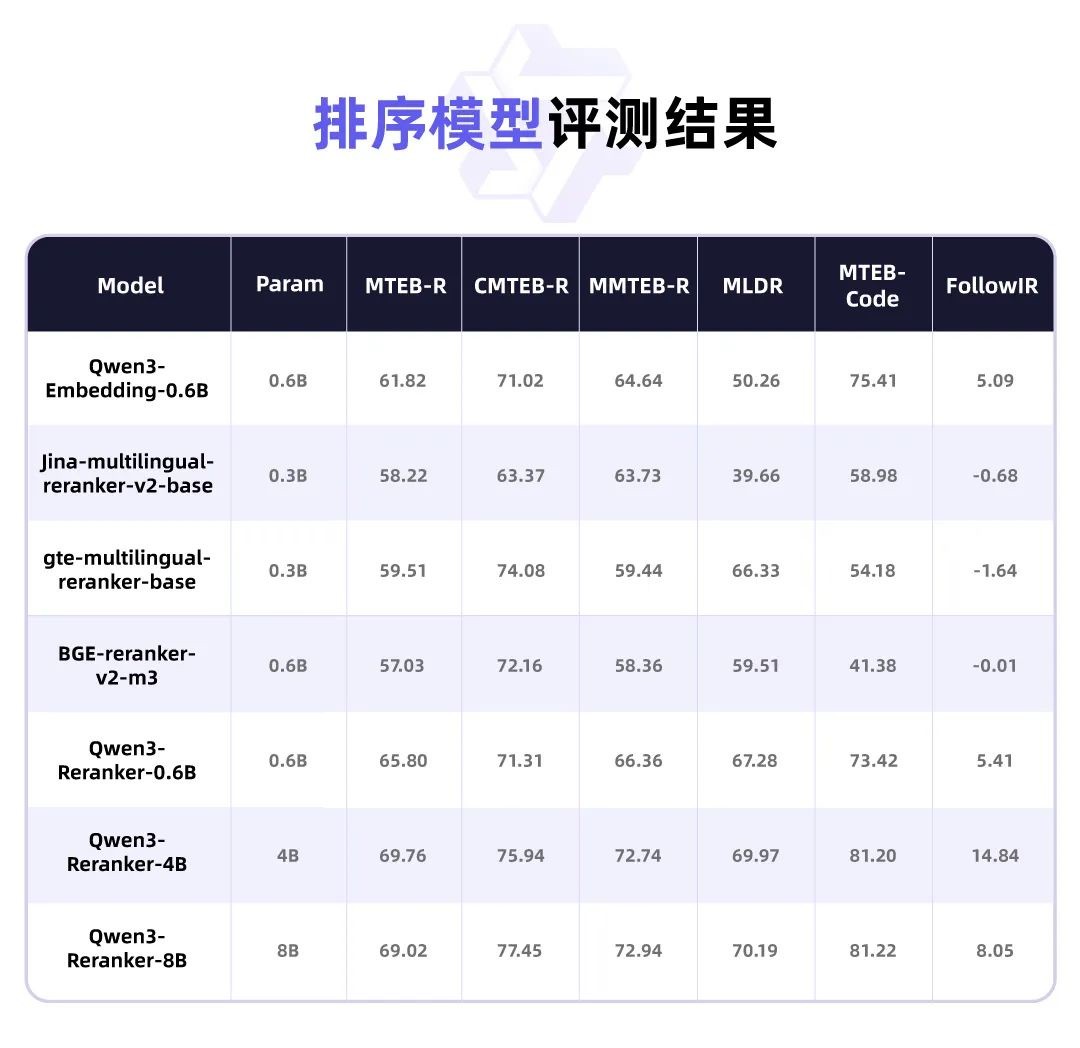 Currently, this series of models has been open-sourced on Hugging Face, ModelScope, and GitHub platforms, and users can also directly use the latest text vector model services provided by Alibaba Cloud's Bai Lian platform
Currently, this series of models has been open-sourced on Hugging Face, ModelScope, and GitHub platforms, and users can also directly use the latest text vector model services provided by Alibaba Cloud's Bai Lian platform
