
DeepSeek OCR paper ignites the internet! Andrej Karpathy: I really like it; Musk: 99% of the future is photons

DeepSeek OCR 論文引發熱議,AI 專家 Andrej Karpathy 表示非常喜歡,認為其是一個優秀的 OCR 模型。他探討了像素作為 LLM 輸入的潛力,認為像素可能比文本更優越,提出四大理由支持這一觀點,包括更高的信息壓縮效率、通用性、雙向注意力處理的優勢以及對 Tokenizer 的批評。
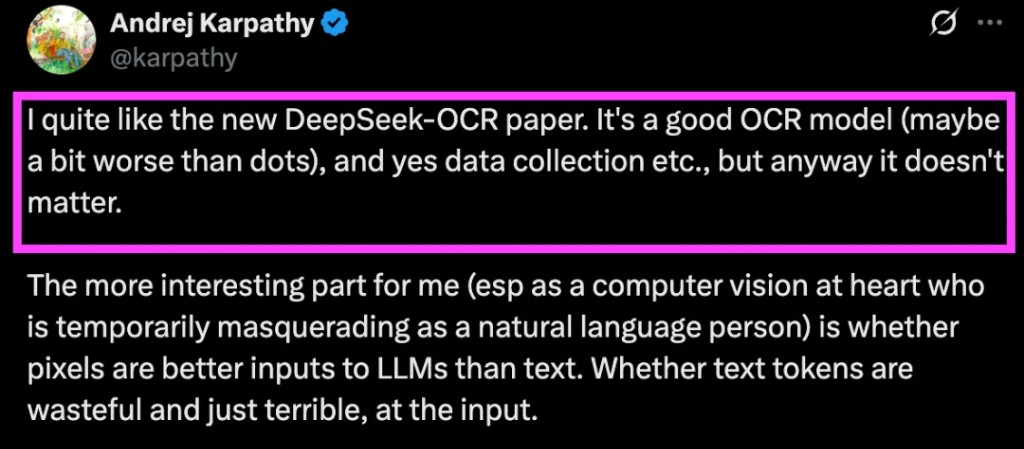
剛剛,AI 大神 Andrej Karpathy 表示非常喜歡 DeepSeek OCR 論文,原話:
我相當喜歡新的 DeepSeek-OCR 論文。它是一個很好的 OCR 模型(可能比 dots 稍微差一點),是的,數據收集等等,但無論如何都不重要。對我來説更有趣的部分(尤其是作為一個以計算機視覺為核心,暫時偽裝成自然語言的人)是像素是否比文本更適合作為 LLM 的輸入。文本標記是否浪費且糟糕,作為輸入。
還不知什麼情況的看我昨天的文章:DeepSeek 王炸:10 倍壓縮率,97% 解碼精度!上下文光學壓縮登場
Karpathy 認為,拋開模型本身不談,deepseek 這篇論文引出了一個更值得深思的問題:對於 LLM 來説,像素是否是比文本更優越的輸入形式?文本 Token 是否既浪費又糟糕?
他進一步設想,或許所有 LLM 的輸入都只應該是圖像。即便是純文本內容,也應該先渲染成圖片再輸入給模型
Karpathy 給出了支持這一構想的四大核心理由:
1. 更高的信息壓縮效率
將文本渲染成圖像,可以實現更高的信息壓縮,這意味着更短的上下文窗口和更高的運行效率
2. 更通用的信息流
像素是一種遠比文本更通用的信息流。它不僅能表示純文本,還能輕鬆捕捉粗體、彩色文本,甚至是任意的圖表和照片
3. 默認實現強大的雙向注意力
像素化的輸入可以很自然、很輕鬆地默認使用雙向注意力進行處理,這種處理方式比自迴歸注意力更為強大
4. 徹底淘汰 Tokenizer
Karpathy 毫不掩飾自己對 Tokenizer 的嫌棄。他認為 Tokenizer 是一個醜陋、獨立、非端到端的階段。它引入了 Unicode 和字節編碼的所有醜陋之處,繼承了大量歷史包袱,並帶來了安全和越獄風險(例如連續字節問題)
他舉例説,Tokenizer 會導致兩個在人眼看來完全相同的字符,在網絡內部被表示為兩個完全不同的 Token。一個笑臉 emoji,在模型看來只是一個奇怪的 Token,而不是一個由像素構成的、真實的笑臉,這導致模型無法利用其視覺信息帶來的遷移學習優勢。Tokenizer 必須消失,他強調
Karpathy 總結道,OCR 只是眾多視覺到文本(vision -> text)任務中的一種。而傳統的文本到文本(text -> text)任務,完全可以被重構成視覺到文本任務,反之則不行
他設想的未來交互模式可能是:用户的輸入(Message)是圖像,而解碼器(Assistant 的響應)的輸出仍然是文本。因為如何真實地輸出像素,或者是否有必要這樣做,目前還不明確
核心爭議:雙向注意力與圖像分塊
對於 Karpathy 的觀點,AI 學者 Yoav Goldberg 提出了兩個疑問:
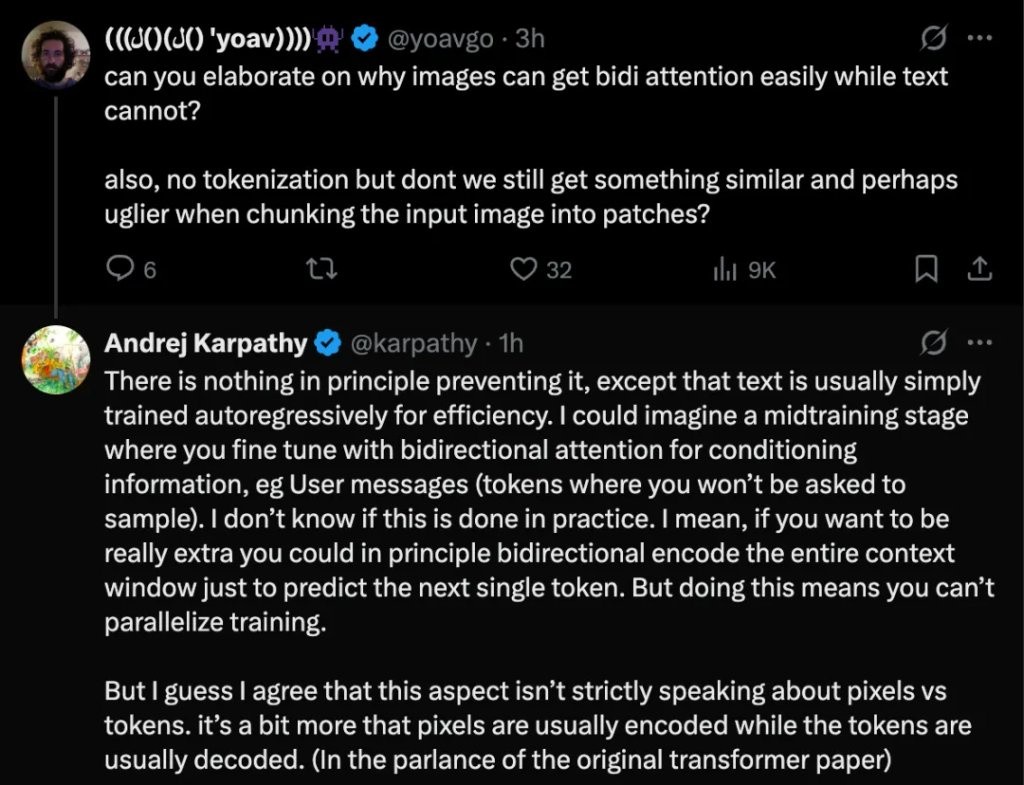
1.為什麼説圖像能輕鬆獲得雙向注意力,而文本不能?
2.雖然沒有了 Tokenization,但將輸入圖像切分成圖塊(Patches),難道不是一種類似且可能更醜陋的處理方式嗎?
Karpathy 對此進行了解釋。
他回應説,原則上沒有任何東西阻止文本使用雙向注意力。但為了效率,文本通常都是以自迴歸的方式進行訓練的。他設想,可以在訓練中期加入一個微調階段,用雙向注意力來處理作為條件的信息(比如用户的輸入消息,因為這些 Token 不需要模型去生成)。但他不確定在實踐中是否有人這樣做。理論上,為了預測下一個 Token,甚至可以對整個上下文窗口進行雙向編碼,但這將導致訓練無法並行化
最後他補充道,或許這個方面(雙向注意力)嚴格來説並非像素與 Token 的本質區別,更多是像素通常被編碼(encoded),而 Token 通常被解碼(decoded)(借用原始 Transformer 論文的術語)
馬斯克:未來 99% 是光子
在這場討論的最後,Elon Musk 也現身評論區,並給出了一個更具未來感的判斷:

從長遠來看,AI 模型超過 99% 的輸入和輸出都將是光子。沒有其他任何東西可以規模化
馬斯克的這條評論並非隨口一説。他進一步補充了一段堪稱硬核的宇宙學科普,來解釋為什麼他認為 “光子” 是終極的規模化方案
簡單來説,宇宙中絕大多數的粒子都是光子
而這些光子最主要的來源,是宇宙微波背景(CMB)。根據測算,CMB 的光子密度約為每立方厘米 410 個。將這個密度乘以可觀測宇宙的巨大體積(半徑約 465 億光年),可以得出僅 CMB 貢獻的光子數量就達到了一個驚人的數字:約 1.5 x 10⁸⁹個
相比之下,所有恆星發出的光子(星光)以及其他來源(如中微子背景、黑洞輻射等)貢獻的數量,則完全可以忽略不計
這背後揭示的物理事實是:光子在數量級上擁有無與倫比的優勢。這或許就是馬斯克認為 AI 的未來輸入輸出將由光子主宰的底層邏輯
AI 寒武紀,原文標題:《DeepSeek OCR 論文引爆網絡!Andrej Karpathy:我很喜歡;馬斯克:未來 99% 都是光子》
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用户特殊的投資目標、財務狀況或需要。用户應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
