
微软 Azure OpenAI 支持数据微调啦!可打造专属 ChatGPT

让 ChatGPT 完全按照你的数据来生成内容。
10 月 17 日,微软在官网宣布,现在可以在 Azure OpenAI 公共预览版中对 GPT-3.5-Turbo、Babbage-002 和 Davinci-002 模型进行数据微调。
使得开发人员通过自己的数据集,便能打造独一无二的 ChatGPT。例如,通过海量医疗数据进行微调,构建专注医疗领域的 ChatGPT 助手,可询问与医疗相关的病历、专业术语、治疗方案等内容。
目前,全球各行业积累了几年甚至几十年的巨量优质数据,如何高效利用、查询这些数据成为一大难题。
通过自有数据微调打造的 AI 助手可有效解决这一痛点,同时提升内容的准确性、安全性,是组织实现降本增效的利器。
什么是数据微调
大模型数据微调(Fine-tuning)是一种迁移学习方法,用于深度学习和机器学习。通常数据微调是基于一个预训练好的模型(例如,GPT-3.5-Turbo)作为基石,然后在特定的任务数据集(例如,法律、医疗、营销)上进行额外的训练,使模型能生成特定业务领域的内容。
例如,你想训练一个模型来回答法律相关的问题,首先在大量的通用文本数据上进行预训练,然后在医学问答数据集上进行微调。
简单来说,微调功能就是让 ChatGPT,完全按照你的数据来生成内容。
需要注意的是,即便你有高质量的数据集,但选择的微调模型性能很差,生成的内容也不会很理想。
而微软提供基于 OpenAI 的 GPT-3.5-Turbo,是一个经过全球数百万开发者验证的高性能成熟模型。
Azure OpenAI 新功能
Babbage-002 和 Davinci-002 是微软最新推出的 GPT-3 基础模型,可生成文本、代码等,没有接受过遵循指令的训练。但在微调、托管服务费用方面更便宜。
Babbage-002 取代了已弃用的 Ada 和 Babbage 模型, Davinci-002 则取代了 Curie 和 Davinci。
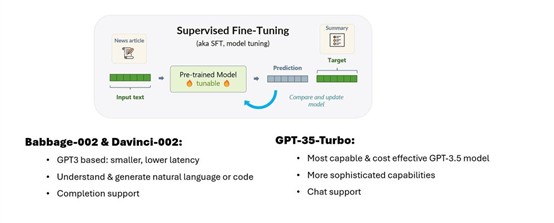
GPT-3.5-Turbo 是 OpenAI 性能最成熟模型之一,支持多轮深度对话、创建微调数据集、训练和部署等一站式开发服务。
Azure OpenAI 微调功能演示
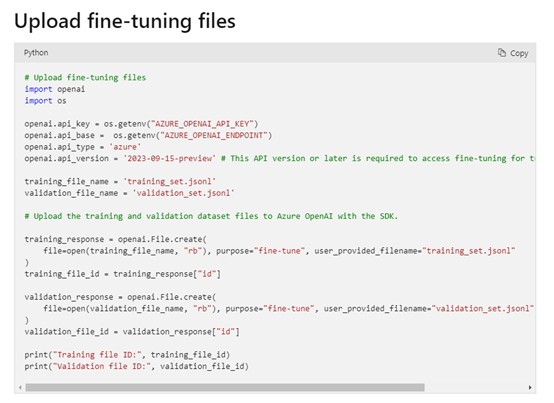
上传数据:微软在 Azure OpenAI 内置了数据过滤功能,当检测到用户上传的数据集包含非法、歧视等有害信息时,会自动删除这些内容。以下是上传数据集代码示例。
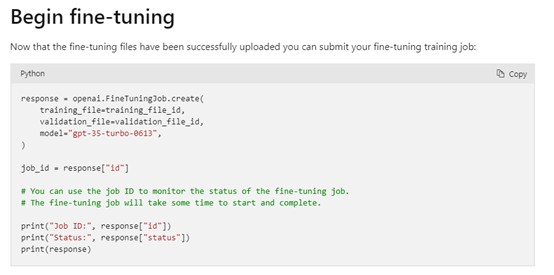
预训练:使用指定模型、训练和验证数据,并设置相应的参数。开发者可将 Azure OpenAI Studio 用于简单的 GUI,或者使用微软的 REST API 或 OpenAI Python SDK。
开始启动微调功能。
完成微调后,将返回评估指标,例如,训练和验证损失等参数。
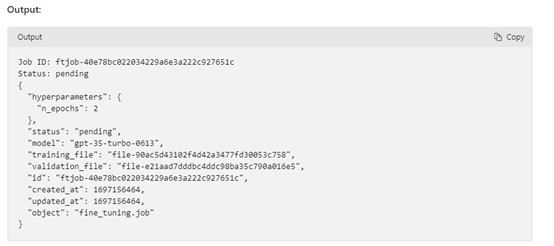
目前,微软提供数据微调托管服务,用户无需担心任何算力资源问题,只需要选择时间即可。
收费标准:Babbage-002 为 34 美元/小时;Davinci-002 为 68 美元/小时;GPT-3.5-Turbo 为 102 美元/小时。
Azure OpenAI 服务中的推理托管
当用户完成微调后,就可以使用模型生成专属内容了。
如果你没有足够的算力资源平台来支撑模型的日常输出,微软同样提供了托管服务。
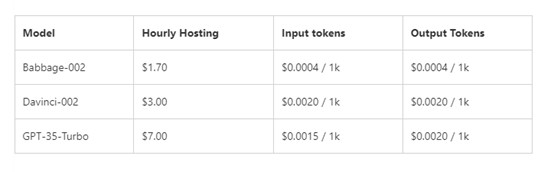
收费标准:Babbage-002 托管每小时 1.7 美元,Davinci-002 每小时 1.7 美元,GPT-35-Turbo,每小时 7 美元。
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。
