
芯片專家詳解刷屏的 Groq 芯片

芯片專家詳解刷屏的 Groq 芯片,Groq 速度更快,核心技術是 LPU,但成本太高,還不能成為英偉達的競爭對手。Groq 公司成立於 2016 年,去年 11 月曾與馬斯克的 Grok 公司發生商標爭議。Groq 雲服務上線後獲得好評,被稱為低延遲產品的 “遊戲規則改變者”,有望對 GPU 在人工智能應用需求方面實現 “革命性提升”,可能成為英偉達 A100 和 H100 芯片的有力替代品。
財報發佈前兩天,英偉達突然冒出來一個勁敵。
一家名叫 Groq 的公司今天在 AI 圈內刷屏,殺招就一個:快。
在傳統的生成式 AI 中,等待是稀鬆平常的事情,字符一個個蹦出,半天才能回答完畢。但在 Groq 今天開放的雲服務體驗平台上,你看到的會是一秒一屏。當模型收到提示後,幾乎能夠立即生成答案。這些答案不僅真實可信,還附有引用,長度更是達到數百個單詞。
電子郵件初創企業 Otherside AI 的首席執行官兼聯合創始人馬特·舒默(Matt Shumer)在演示中親自體驗了 Groq 的強大功能。他稱讚 Groq 快如閃電,能夠在不到一秒鐘的時間內生成數百個單詞的事實性、引用性答案。更令人驚訝的是,它超過 3/4 的時間用於搜索信息,而生成答案的時間卻短到只有幾分之一秒。
雖然今天才刷屏,但 Groq 公司並非初出茅廬的新創企業。實際上,該公司成立於 2016 年,並在那時就註冊了 Groq 商標。去年 11 月,當馬斯克發佈人工智能模型 Grok 時,Groq 公司的開發者們就發了一篇文章説馬斯克撞名自己的公司。信寫的挺逗的,但這波流量他們是一點沒吃到。

這一次他們之所以能突然爆發,主要是因為 Groq 雲服務的上線,讓大家真的能親身感受一下不卡頓的 AI 用起來有多爽。
有從事人工智能開發的用户稱讚,Groq 是追求低延遲產品的 “遊戲規則改變者”,低延遲指的是從處理請求到獲得響應所需的時間。另一位用户則表示,Groq 的 LPU 在未來有望對 GPU 在人工智能應用需求方面實現 “革命性提升”,並認為它可能成為英偉達 A100 和 H100 芯片的 “高性能硬件” 的有力替代品。
Groq 芯片,能在速度上取勝的核心技術是 LPU
根據其模型的首次公開基準測試結果,Groq 雲服務搭載的 Llama2 或 Mistreal 模型在計算和響應速度上遠超 ChatGPT。這一卓越性能的背後,是 Groq 團隊為大語言模型(LLM)量身定製的專用芯片(ASIC),它使得 Groq 每秒可以生成高達 500 個 token。相比之下,目前 ChatGPT-3.5 的公開版本每秒只能生成大約 40 個 token。
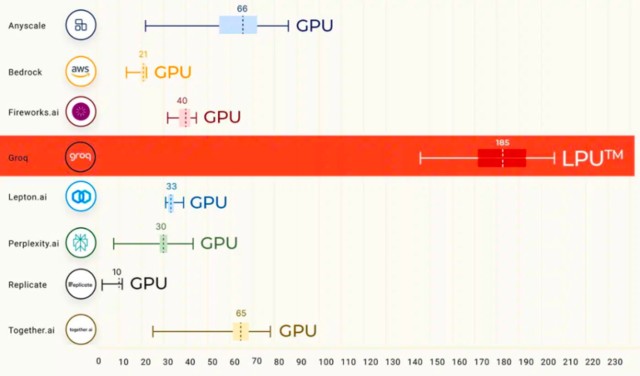
這一芯片能在速度上取勝的核心技術是 Groq 首創的 LPU 技術。
根據推特上與 Groq 關係密切的投資人 k_zeroS 分享,LPU 的工作原理與 GPU 截然不同。它採用了時序指令集計算機(Temporal Instruction Set Computer)架構,這意味着它無需像使用高帶寬存儲器(HBM)的 GPU 那樣頻繁地從內存中加載數據。這一特點不僅有助於避免 HBM 短缺的問題,還能有效降低成本。

不同於 Nvidia GPU 需要依賴高速數據傳輸,Groq 的 LPU 在其系統中沒有采用高帶寬存儲器(HBM)。它使用的是 SRAM,其速度比 GPU 所用的存儲器快約 20 倍。
鑑於 AI 的推理計算相較於模型訓練需要的數據量遠小,Groq 的 LPU 因此更節能。在執行推理任務時,它從外部內存讀取的數據更少,消耗的電量也低於 Nvidia 的 GPU。
如果在 AI 處理場景中採用 Groq 的 LPU,可能就無需為 Nvidia GPU 配置特殊的存儲解決方案。LPU 並不像 GPU 那樣對存儲速度有極高要求。Groq 公司宣稱,其技術能夠通過其強大的芯片和軟件,在 AI 任務中取代 GPU 的角色。
另一位安卡拉大學的助教更形象的解釋了一下 LPU 和 GPU 的差別,“想象一下,你有兩個工人,一個來自 Groq(我們稱他們為 “LPU”),另一個來自 Nvidia(我們稱之為 “GPU”)。兩人的任務都是儘快整理一大堆文件。
GPU 就像一個速度很快的工人,但也需要使用高速傳送系統(這就像高帶寬存儲器或 HBM)將所有文件快速傳送到他們的辦公桌上。這個系統可能很昂貴,有時很難得到(因為 HBM 產能有限)。
另一方面,Groq 的 LPU 就像一個高效組織任務的工人,他們不需要那麼快地交付文件,所以用了一張就放在他們身邊的更小的桌子(這就像 SRAM,一種更快但更小的存儲器),所以他們幾乎可以立即獲得所需的東西。這意味着他們可以在不依賴快速交付系統的情況下快速工作。
對於不需要查看堆中每一篇文件的任務(類似於不使用那麼多數據的人工智能任務),LPU 甚至更好。它不需要像往常一樣來回移動,既節省了能源,又能快速完成工作。

LPU 組織工作的特殊方式(這是時態指令集計算機體系結構)意味着它不必一直站起來從堆裏搶更多的論文。這與 GPU 不同,GPU 不斷需要高速系統提供更多的文件。”
運用 LPU 這一技術,Groq 生產了加速器單元,根據其網站介紹規格如下:

確實快,但是貴,目前並不能成為英偉達的競爭對手
在 Groq 剛剛刷屏的時候,AI 行業都沉浸在它閃電速度的震撼之中。然而震撼過後,很多行業大佬一算賬,發現這個快的代價可能有點高。
賈揚清在推特上算了一筆賬,因為 Groq 小的可憐的內存容量(230MB),在運行 Llama-2 70b 模型時,需要 305 張 Groq 卡才足夠,而用 H100 則只需要 8 張卡。從目前的價格來看,這意味着在同等吞吐量下,Groq 的硬件成本是 H100 的 40 倍,能耗成本是 10 倍。

芯片專家姚金鑫(J 叔)向騰訊科技進行了更詳細的解釋:
按照 Groq 的信息,這顆 AI 芯片的規格如下:
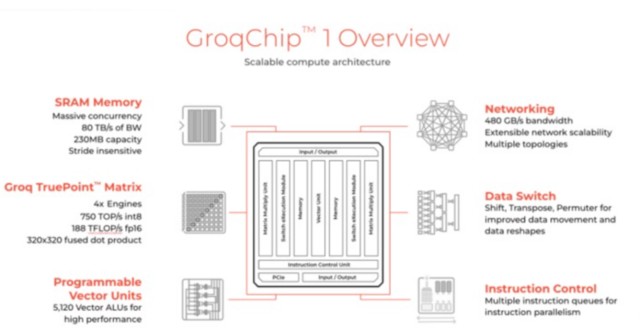
從芯片的規格中,可以看到幾個關鍵信息點:SRAM 的容量是 230MB,帶寬 80TB/s,FP16 的算力是 188TFLOPs。
按照當前對大模型的推理部署,7B 的模型大約需要 14G 以上的內存容量,那麼為了部署一個 7B 的模型,大約需要 70 片左右的芯片,根據透露的信息,一顆芯片對應一張計算卡,按照 4U 服務器配置 8 張計算卡來計算,就需要 9 台 4U 服務器(幾乎佔了一個標準機櫃了),總共 72 顆計算芯片,在這種情況下,算力(在 FP16 下)也達到了驚人的 188T * 72 = 13.5P,如果按照 INT8 來算就是 54P。54P 的算力來推理 7B 的大模型,用大炮打蚊子來形容一點也不為過。
目前社交媒體廣泛傳播的文章對標的是英偉達 H100,其採用的是 80G 的 HBM,這個容量可以部署 5 個 7B 的大模型實例;我們再來看算力,稀疏化後,H100 在 FP16 下的算力將近 2P,在 INT8 上也將近 4P。
那麼就可以做個對比,如果從同等算力來看,如果都是用 INT8 來推理,採用 Groq 的方案需要 9 台包含 72 片的服務器集羣,而如果是 H100,達到同等算力大約需要 2 台 8 卡服務器,此時的 INT8 算力已經到 64P,可以同時部署的 7B 大模型數量達到 80 多個。
原文中提到,Groq 對 Llama2-7B 的 Token 生成速度是 750 Tokens/s,如果對標的是 H100 服務器,那這 2 台總共 16 顆的 H100 芯片,併發吞吐就高到不知道哪裏去了。如果從成本的角度,9 台的 Groq 服務器,也是遠遠貴過 2 台 H100 的服務器(即使此刻價格已經高到離譜)。
● Groq:2 萬美金 *72=144 萬美金,服務器 2 萬美金 *9=18 萬美金,純的 BOM 成本 160 萬美金以上(全部都是按照最低方式來計算)。
● H100:30 萬美金 *2 = 60 萬美金(國外),300 萬人民幣 *2=600 萬人民幣(國內實際市場價)
如果是 70B 的模型,同樣是 INT8,要用到至少 600 張卡,將近 80 台服務器,成本會更高。
這還沒有算機架相關費用,和消耗的電費(9 台 4U 服務器幾乎佔用整個標準機櫃)。
實際上,部署推理性價比最高的,恰恰是 4090 這種神卡。
Groq 是否真的超越了英偉達?對此,姚金鑫(J 叔)也表達了自己不同的看法:
“英偉達在本次 AI 浪潮中的絕對領先地位,使得全球都翹首以盼挑戰者。每次吸引眼球的文章,總會在最初被人相信,除了這個原因之外,還是因為在做對比時的 “套路”,故意忽略其他因素,用單一維度來做比較。這就好比那句名言 “拋開事實不談,難道你就沒有一點錯的地方嗎?”
拋開場景來談對比,其實是不合適的。對於 Groq 這種架構來講,也有其盡顯長處的應用場景,畢竟這麼高的帶寬,對許多需要頻繁數據搬運的場景來説,那就是再好不過了。
總結起來,Groq 的架構建立在小內存,大算力上,因此有限的被處理的內容對應着極高的算力,導致其速度非常快。
現在把句話反過來,Groq 極高的速度是建立在很有限的單卡吞吐能力上的。要保證和 H100 同樣吞吐量,你就需要更多的卡。
速度,在這裏成了 Groq 的雙刃劍。
傳奇 CEO,小團隊
雖然 Groq 還面對着很多潛在的問題,但它還是讓人看到了 GPU 之外的可能路徑。這主要得益於其背後的超強團隊。
Groq 的 CEO 是被稱為 “TPU 之父” 的前谷歌員工喬納森·羅斯;聯合創始人道格拉斯·懷特曼也來自谷歌 TPU 團隊,並先後創立了四家公司。該公司首席技術官吉姆·米勒曾是亞馬遜雲計算服務 AWS 設計算力硬件的負責人,CMO 曾主導了蘋果 Macintosh 的市場發佈。
Groq 目前的團隊也相對較小,其總部位於加州山景城,該公司僅有 180 餘名員工,甚至還不到英特爾等大型芯片製造商所需工程師數量的四分之一。
羅斯等人的目標是在 Groq 複製他在谷歌的成功經驗,打造一個內部芯片項目,引領整個行業向新技術邁進。他希望吸引少數關鍵客户,通過廣泛部署 Groq 芯片為公司提供穩定的收入來源,推動公司的獨立發展。目前,這家初創公司已開始向潛在客户發送樣品。
“這就像獵殺大象,” 羅斯説道,“你只需要少數獵物就能維持自己的生命,尤其在我們還如此弱小的時候。”
本文作者:郝博陽、郭曉靜,來源:騰訊科技,原文標題:《芯片專家詳解刷屏的 Groq 芯片:目前並不能替代英偉達》
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用户特殊的投資目標、財務狀況或需要。用户應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
