
The key model behind Sora, the breakthrough to achieving AGI?
Transformer 對 Diffusion 過程的貢獻類似於引擎升級。
橫空出世的 Sora,以碾壓其他文生視頻模型的姿態,讓全球影視行業從業者瑟瑟發抖,繼續為狂飆的 AI 熱潮注入了一針強心劑,也進一步鞏固了 OpenAI 作為 GenAI 尖端技術領頭羊的身份。
不過,驅動 Sora 的技術,其實是早早幾年前就已經出現在人工智能研究領域的 Diffusion Transformer 架構。
這一架構最出色的地方就在於,它可以讓 AI 模型的規模,突破以往的技術限制,即參數規模越大、訓練時長越長、訓練數據集越大,生成視頻的效果更好。Sora 就是這樣一個 “大力出奇跡” 的產物。
什麼是 Diffusion Transformer
在機器學習中,有兩個關鍵概念:1)Diffusion;2)Transformer。
首先來説 Diffusion,大多數可以生成圖像、視頻的 AI 模型,包括 OpenAI 的 DALL-E3,都依賴於一種叫做 Diffusion 的過程來輸出圖像、視頻、音頻等內容。
Diffusion 的工作原理,是通過連續添加高斯噪聲來破壞訓練數據(前向過程,forward),然後通過反轉這個噪聲(逆向過程,reverse),來學習恢復數據。即首先將隨機採樣的噪聲傳入模型中,通過學習去噪過程來生成數據。
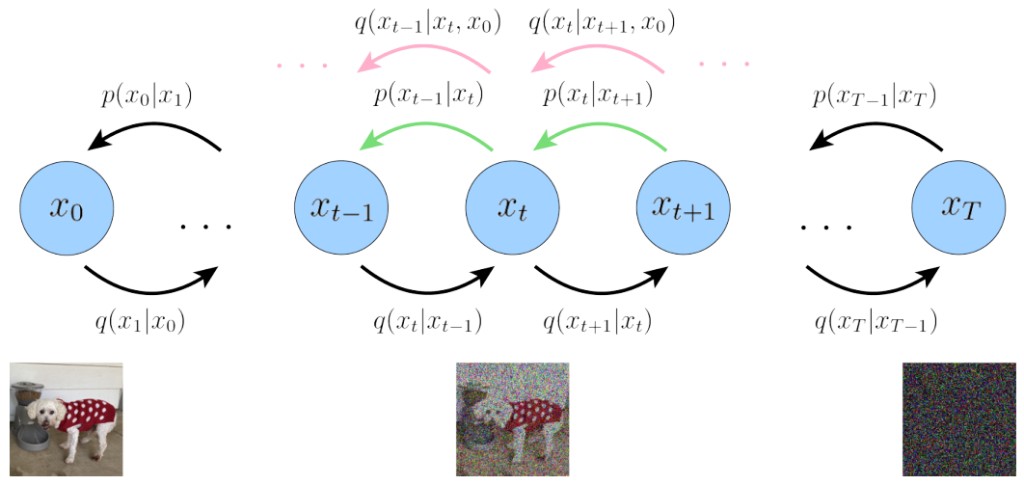
在模型的逆向過程中,diffusion 需要依賴一個叫做 U-Net 的引擎,來學習估計要去除的噪聲。但 U-Net 非常複雜,其專門設計的模塊會大大降低 diffusion 生成數據的速度。
Transformer 則是目前主流 LLM 如 GPT-4、Gemini 等模型背後的技術基礎。它可以取代 U-Net,提高 Diffusion 過程的效率。Transformer 有着獨特的 “注意力機制”。對於每一條輸入數據(如 Diffusion 中的圖像噪聲),Transformer 都會權衡其他每一條輸入(圖像中的其他噪聲)的相關性,並從中學習,生成結果(圖像噪聲的估計值)。
注意力機制不僅使 Transformer 比其他模型架構更簡單,而且使架構可並行化。簡單來説,也就是説可以訓練出越來越大的 Transformer 模型,同時顯著提高計算能力。
Diffusion Transformer 這個概念由紐約大學計算機教授謝賽寧與 William Peebles(現任 OpenAI Sora 的聯合主管)共同提出。
謝賽寧教授在接受媒體採訪時表示:
Transformer 對 Diffusion 過程的貢獻類似於引擎升級。Transformer 的引入......標誌着可擴展性和有效性的重大飛躍。這一點在 Sora 等模型中體現得尤為明顯,這些模型得益於對海量視頻數據的訓練,並利用更高的模型參數來展示 Transformer 在大規模應用時的變革潛力。
Sora 是 “大力出奇跡” 的產物
根據華福證券的分析,Sora 生成視頻的過程,大致如下:
視頻編碼:VisualEncoder 將原始視頻壓縮為低維潛在空間,再將視頻分解為時空 patches 後拉平為系列視頻 token 以供 transformer 處理。
加噪降噪:在 transfomer 架構下的擴散模型中,時空 patches 融合文本條件化,先後經過加噪和去噪,以達到可解碼狀態。
視頻解碼:將去噪後的低維潛在表示映射回像素空間。

可以看到,Sora 的主要特點就是採用 transformer 替代了 U-Net 引擎。分析師施曉俊認為,Sora 替換 U-Net 為 DiT 的 transformer 作為模型架構,具有兩大優勢:
1)Transformer 可將輸入視頻分解為 3Dpatch,類似 DiT 將圖片分解為圖塊,不僅突破了分辨率、尺寸等限制,而且能夠同時處理時間和空間多維信息;
2)Transformer 延續了 OpenAI 的 ScalingLaw,具有較強的可拓展性,即參數規模越大、訓練時長越長、訓練數據集越大,生成視頻的效果更好。例如,Sora 隨着訓練次數的增加,小狗在雪地裏的視頻質量顯著提升。
然而,Transformer 最大的缺點就是——貴。
其全注意力機制的內存需求會隨輸入序列長度而二次方增長,因此高分辨率圖像處理能力不足。在處理視頻這樣的高維信號時,Transformer 的增長模式會讓計算成本變得非常高。
換句話説,Sora 的誕生,是背靠微軟的 OpenAI 瘋狂燒算力的結果。相比於 U-Net 架構,Transformer 突顯 ScalingLaw 下的 “暴力美學”,即參數規模越大、訓練時長越長、訓練數據集越大,生成視頻的效果更好;此外,在 Transformer 大規模訓練下,逐步顯現出規模效應,迸發了模型的湧現能力。
