
申萬宏源:KIMI 確認爆款!國內語言大模型正式達到 GPT-4 水平

申萬宏源證券表示,月之暗面的 KIMI AI 產品在大模型長文本能力上取得突破,達到了 GPT-4 水平。KIMI 能夠精準定位辦公人羣,適用於高效閲讀、專業文件解讀、資料查詢和整理等方面。KIMI 的上下文能力已達到 200 萬字,支持全文總結和生成、聯網搜索以及數據處理等多種實用場景。KIMI 的用户活躍度也在持續提升。
核心觀點
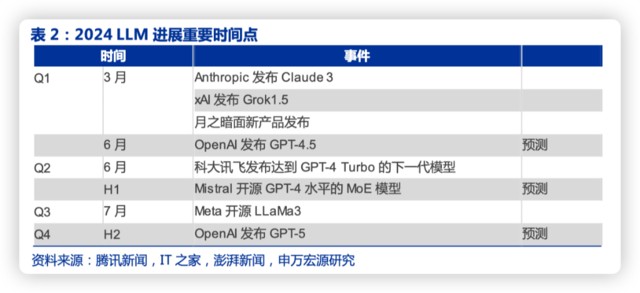
1)市場可能認為海外大模型迭代放緩,但我們認為 2024 年模型能力仍然快速迭代。包括 OpenAI 以外的其他模型能力追趕、Llama3 等開源大模型發佈、下半年 OpenAI 的新模型迭代等;
2)市場可能認為國產大模型能力與海外差距極大,無法支撐任何應用,我們認為 kimi 等表明國產文字大模型能力已經達到 GPT4 水平,期待後續推理、數學、多模態等能力的迭代。
3 月 18 日,月之暗面宣佈其 AI 產品 kimi,在大模型長上下文窗口技術上取得新的突破,Kimi 智能助手已支持 200 萬字超長無損上下文,並於即日起開啓產品內測。Kimichat 是月之暗面推出的對話助手工具,於 2023 年 10 月 10 日發佈,發佈之初即定位長文本。
支持輸入 20 萬漢字,是目前國產大模型中支持的最長上下文輸入長度,2024 年 2 月,kimi 迭代了網站、多問題搜索能力,可用性繼續提升。
3 月,上下文能力達到 200 萬字。
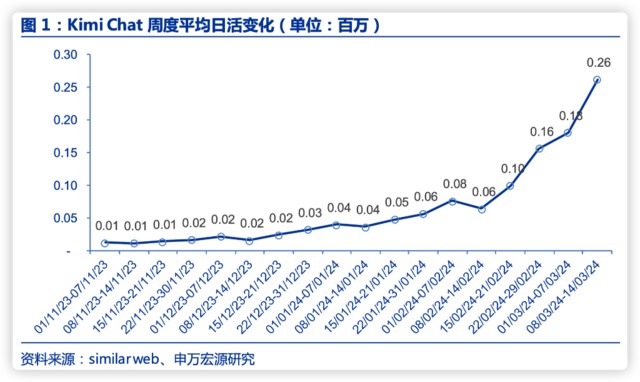
多次迭代後伴隨着 Kimi 用户活躍度提升,2 月平均日活同比上升 101.9%,3 月前二週繼續攀升。
更長的上下文能力意味着更多的實用場景。1)全文總結和生成:通過提問和文件上傳等功能,能夠迅速對眾多文獻和報告進行摘要提煉;2)聯網搜索:能夠搜索實時信息,迅速整合並給出詳盡回答,同時提供信息來源,確保對話的豐富性和準確性;3)數據處理:把繁雜的數據整理成表格,以助於數據分析。除此以外 Kimi 還支持編寫代碼、用户交互、翻譯等功能。
根據我們內部測評,國產大模型 Kimi 文字能力全面達到 GPT-4 水平。Kimi 中英文生成能力已經接近 GPT-4 水平,儘管邏輯推理能力仍有差距,且主打文字生成、目前無多模態能力;Cluade3 中英文生成、理解、推理,多模態圖片理解能力均與 GPT-4 接近,效果好於 Gemini,且實際使用中生成速度快於 GPT-4 和 Gemini。
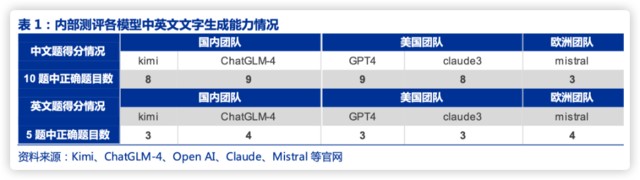
我們認為其在長文本單點能力上實現突破,精準定位辦公人羣。Kimi 支持 200 萬漢字的長文本輸入,對比來看,GPT-4Turbo-128k 的能力是約 10 萬漢字,Claude3200k 上下文是約 16 萬漢字。因此,Kimi 更適用於高效閲讀、專業文件解讀、資料查詢、資料整理總結等方面。
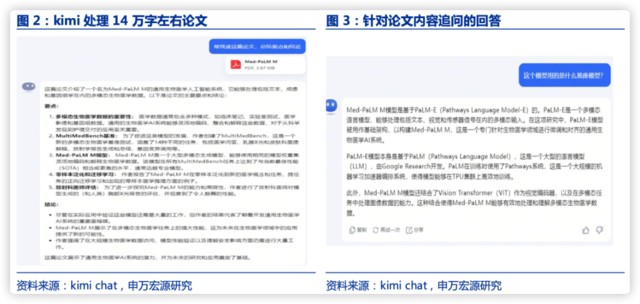
1)專業論文要點歸納總結任務的表現和 GPT4 大致相同,響應迅速,約 10 秒可以讀完論文並給出回答。回答內容簡要,並能夠根據文檔回答追問。
專業論文要點歸納總結任務的表現和 GPT4 大致相同,響應迅速,約 10 秒可以讀完論文並給出回答。回答內容簡要,能夠根據文檔精準回覆追問,體現了模型較好的邏輯推理能力。
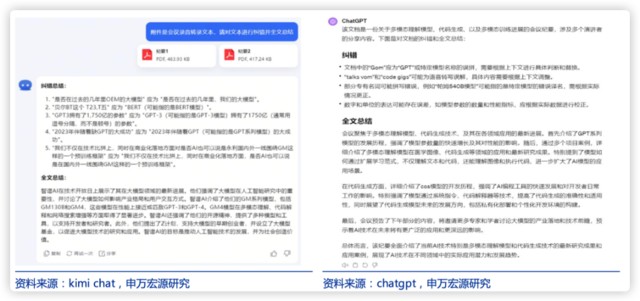
2)資料整理總結方面 kimi 在會議紀要總結能力上具有優勢,選取一場會議的錄音轉錄文本(分成兩份 pdf)給到模型進行文本糾錯和全文總結,kimi 的糾錯能力和總結能力強於 GPT4,例如 kimi 能根據上下文將 “貝爾 BT 這個 T23,T 五” 這個亂碼糾正為 “BERT”,並告知可能指 BERT 模型,其全文總結結果也比 GPT4 結果更具可用性。
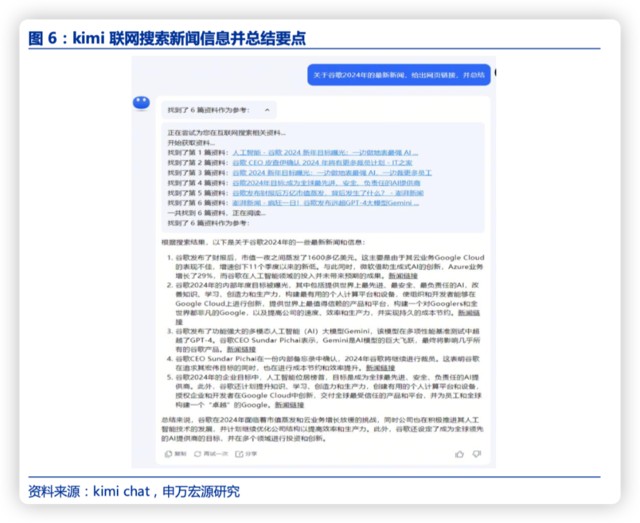
3)能夠針對提問自動聯網搜索總結回答,答案提供信息來源,更具可靠性。例如下圖問 kimi 關於谷歌 2024 的最新新聞,基本涵蓋了所有要點新聞,總結也到位。
總體來説,我們認為 kimi 的優勢在語言理解、長文本處理、邏輯推理能力上,數學解題和多模態能力暫缺或稍弱。其長文本處理能力讓論文總結、會議紀要變得更具可用性,加上聯網搜索功能,對於需要查閲大量信息和處理會議紀要的辦公人羣有極大助力,未來辦公類 AI 應用或將受益。
Kimi 成功啓示:我們認為團隊成員能力、資金儲備、時間可能是 Kimi 目前較為成功的原因。
1)月之暗面(Moonshot)由清華大學交叉信息學院楊植麟教授領銜,團隊成員包括來自 Google、Meta、Amazon 等國際科技巨頭的人才,在 Gemini、盤古 NLP、悟道等多個大模型研發中有參與;
2)公司成立後獲紅杉中國、真格基金等機構投資,最新一輪融資超 10 億美元,投資方包括阿里、紅杉中國、小紅書、美團等,估值達 25 億美金;
3)月之暗面成立於 2023 年 3 月,此時 chatgpt 的全面成功,使得業界大模型已基本確認 Decoder-only+VQA 的技術路線,有效避免了此前由於技術路線分歧造成的開發資源浪費。
截至目前,國內大模型的文字生成能力已經整體接近 GPT-4Turbo。1 月 30 日,上 1 海人工智能實驗室發佈了大模型開源開放評測體系司南(OpenCompass2.0),結果顯示,不少國內廠商近期新發布的模型在多個能力維度上正在快速縮小與 GPT-4Turbo 的差距,包括智譜清言 GLM-4、阿里巴巴 Qwen-Max、百度文心一言 4.0 等。
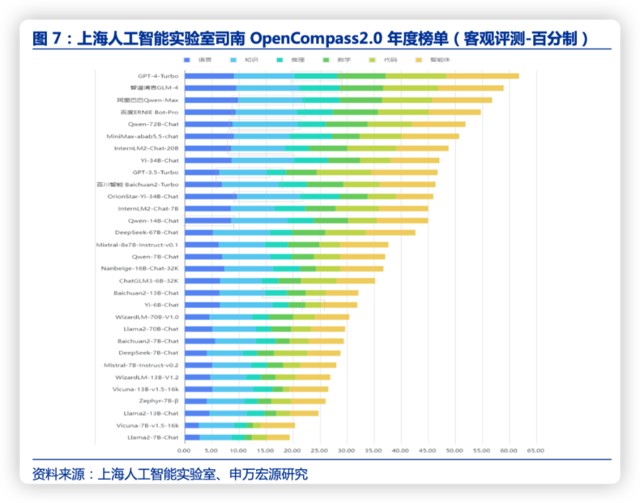
但同時根據評測,複雜推理相關能力是大模型普遍面臨的難題,國內大模型相比於 GPT-4 還存在差距。評測顯示,推理、數學、代碼、智能體是國內大模型的短板。GPT-4Turbo 在涉及複雜推理的場景雖然亦有提升空間,但已明顯領先於國內的商業模型和開源模型。這是大模型在金融、工業等要求可靠的場景落地需要的關鍵能力。
整體來看:
1)市場可能認為海外大模型迭代放緩,但我們認為 2024 年模型能力仍然快速迭代。包括 OpenAI 以外的其他模型能力追趕、Llama3 等開源大模型發佈、下半年 OpenAI 的新模型迭代等;
2)市場可能認為國產大模型能力與海外差距極大,無法支撐任何應用,我們認為 kimi 等表明國產文字大模型能力已經達到 GPT4 水平,期待後續推理、數學、多模態等能力的迭代。
本文作者:證券分析師 洪依真 A0230519060003 劉洋 A0230513050006 林起賢 A0230519060002,來源:申萬宏源證券
