
Kimi hard against the full-blooded version o1 of multimodal, first exposure of training details! Reinforcement learning scaling new paradigm born
Kimi released the k1.5 multimodal thinking model, marking the rise of Chinese programming languages. The model's mathematical, coding, and multimodal reasoning capabilities under the Long CoT mode have reached the level of OpenAI's o1 full version, and it significantly outperforms GPT-4o and Claude 3.5 under the Short CoT mode. The Kimi team innovatively expanded the application of reinforcement learning, opening new pathways to achieve autonomous expansion of training data through a reward mechanism, effectively promoting the scaling of computation
Do you remember that AI guru Karpathy once said, "English is the hottest programming language"?
Now, two years later, this rule is about to be completely overturned.
Starting today, Chinese is very likely to become the world's hottest programming language!

Just now, Kimi released the k1.5 multimodal thinking model. This is the third consecutive month of significant upgrades to the k series reinforcement learning models, following the release of the k0-math mathematical model in November last year and the k1 visual thinking model in December.
The performance of Kimi k1.5 has now fully caught up with the current strongest model in the world—OpenAI o1 full version.
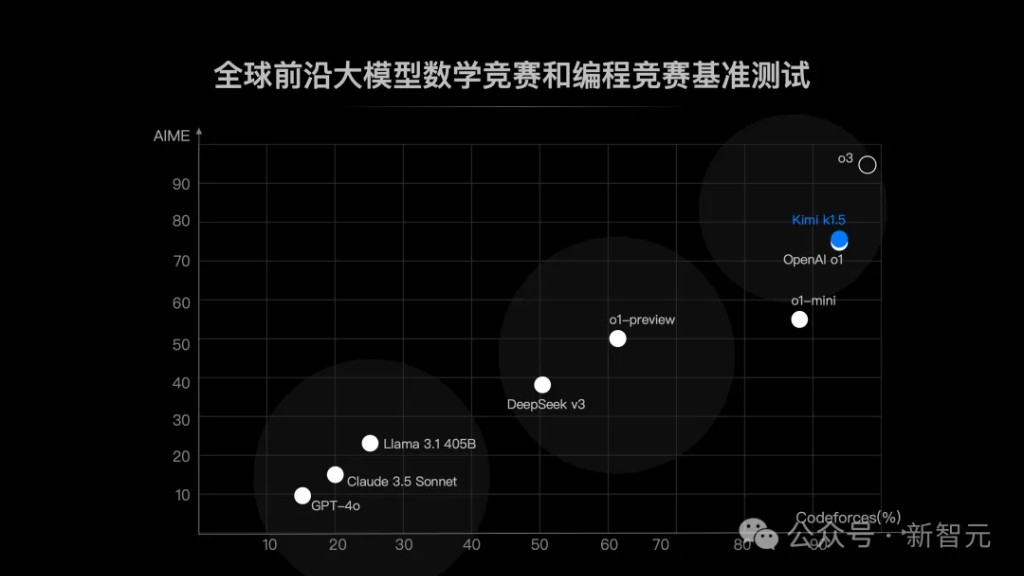
Specifically, in the Long CoT mode, Kimi k1.5's capabilities in mathematics, coding, and multimodal reasoning have reached the level of the long-thinking SOTA model OpenAI o1 full version. This is also the first time a company outside of OpenAI has achieved this globally.
In the Short CoT mode, Kimi k1.5 significantly outperforms GPT-4o and Claude 3.5.
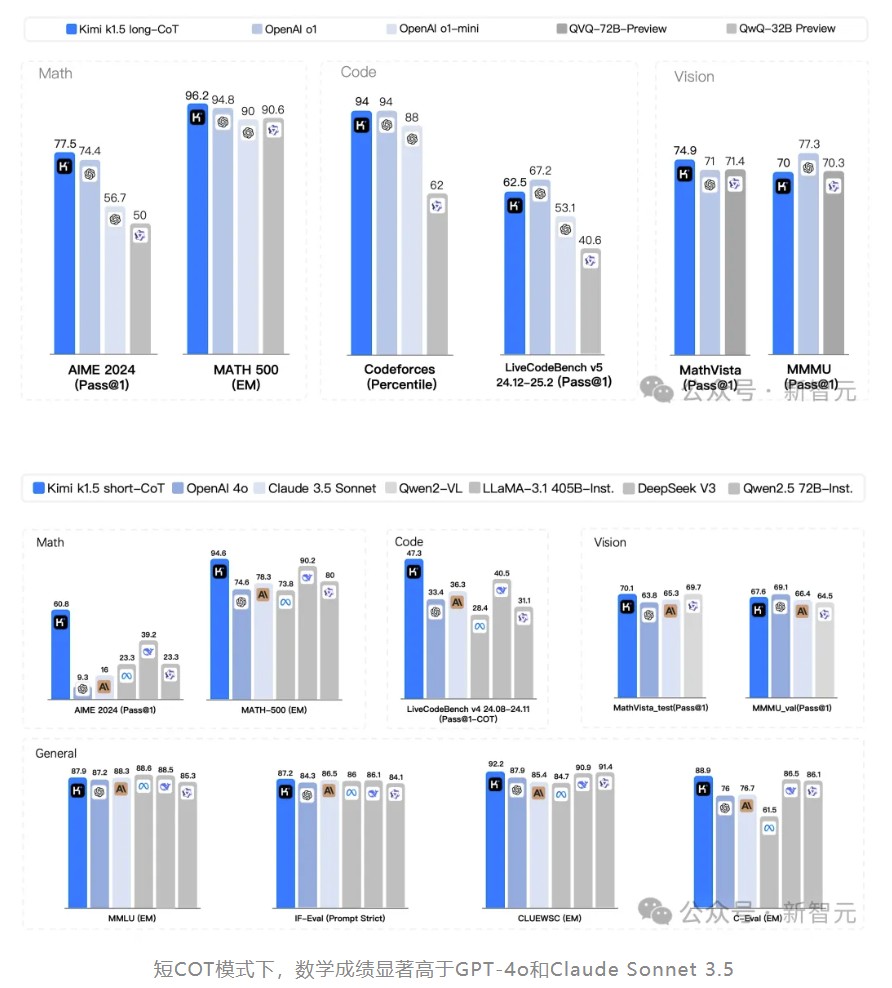
In the Short CoT mode, the mathematical performance is significantly higher than that of GPT-4o and Claude Sonnet 3.5.
At the same time, the Dark Side of the Moon generously disclosed the training technical details of this full-version o1 level reinforcement learning model.
Simple Miracles, Pioneering Long2Short Thinking Chains
By examining Kimi k1.5's 25-page technical report, we can clearly see the technical innovations of this model.
Currently, the scaling of language models based on next token prediction has been effectively proven.
However, model scaling is still limited by the amount of available data. To address this, the Kimi team innovatively expanded the application of reinforcement learning (RL), opening up a new path.
It allows LLMs to engage in exploratory learning through a reward mechanism, thereby autonomously expanding training data and achieving effective scaling of computation.
 Paper address: https://github.com/MoonshotAI/kimi-k1.5
Paper address: https://github.com/MoonshotAI/kimi-k1.5
Below are the four key elements of the design and training of k1.5:
1. Long Context Expansion
2. Improved Strategy Optimization
3. Simplified Framework
4. Multimodal
Next, let's delve into these technical details together.
Context Compression of Short CoT Models
Unlike the complex technical approaches commonly adopted in the industry, the Kimi team chose a more elegant technical route—returning to first principles.
They demonstrated that it is possible to achieve excellent performance without relying on Monte Carlo tree search, value functions, or process reward models.
As seen above, we have already observed significant breakthroughs of Kimi k1.5 in multiple authoritative benchmark tests.
So, how is long2short implemented?
The Kimi team believes that the reasoning prior of the long CoT model can be transferred to the short CoT model, thereby improving performance even under a limited testing token budget.
Model Merging
Merging the long CoT model and the short CoT model not only positively impacts generalization but also improves token usage efficiency.
This method combines a long CoT model with a short model by simply averaging the weights of the two models to obtain a new model without the need for training.
Shortest Filtering Sampling
Due to the significant variation in response lengths generated by the model for the same question, the team designed a shortest filtering sampling method.
That is, first sample n times for the same question, and then select the shortest correct response for supervised fine-tuning.
DPO
Using the long CoT model to generate multiple response samples, the shortest correct solution is selected as the positive sample, while longer responses are treated as negative samples, including correct responses that are 1.5 times the length of the selected positive sample.
These positive and negative samples form paired preference data for DPO training in the dataset.
long2short Reinforcement Learning
After the standard reinforcement learning training phase, the team selected a base model that provides the best balance between performance and token usage efficiency for a separate long2short reinforcement learning training phase.
In the second phase, they applied "length penalties" and significantly reduced the maximum expansion length to further penalize responses that may be correct but exceed the expected length.
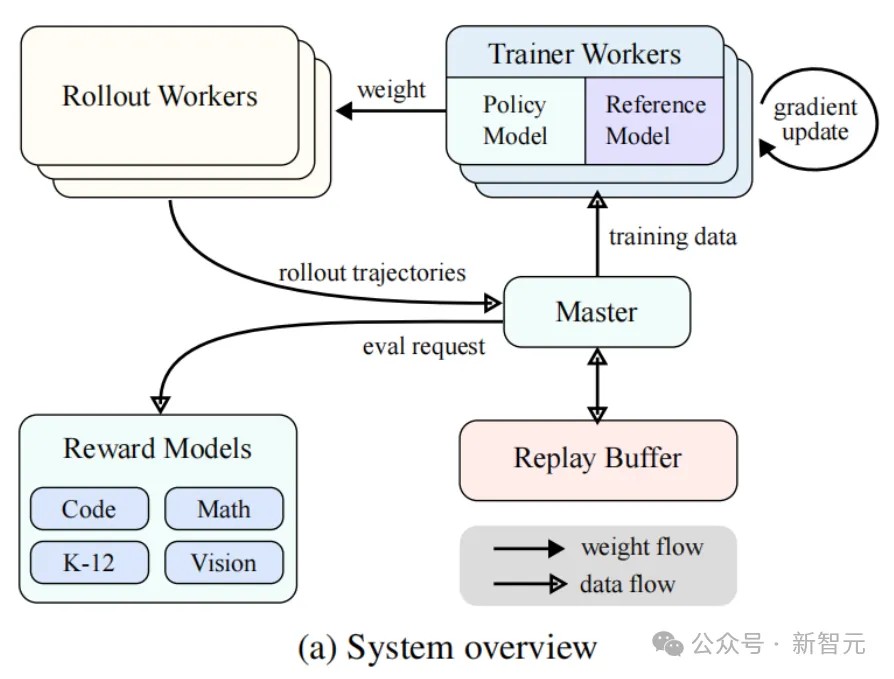
Reinforcement Learning Infrastructure
The Kimi k1.5 system designed an iterative synchronous RL framework aimed at enhancing the model's reasoning ability through continuous learning and adaptation A key innovation of the system is the introduction of Partial Rollout technology to reduce computational overhead and optimize the processing of complex reasoning trajectories.
As shown in Figure 3a, the RL training system operates through an iterative synchronization method, with each iteration consisting of a rollback phase and a training phase.
In the rollback phase, rollback worker nodes coordinated by a central controller generate rollback trajectories by interacting with the model. These trajectories are sequences of responses generated by the model to various inputs. In the subsequent training phase, training worker nodes access these experiences to update the model's weights.
This cyclical process allows the model to continuously learn from its behavior, adjusting its strategy over time to improve performance.
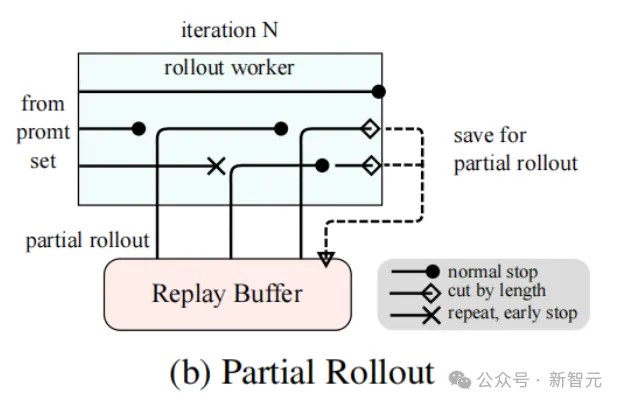
Partial Rollout Technology for Long CoT Reinforcement Learning
Partial Rollouts effectively address the resource allocation and efficiency challenges when handling long CoT characteristics by simultaneously managing the rollbacks of long and short trajectories, thereby scaling long-context reinforcement learning (RL) training.
This technology sets a fixed output token budget, limiting the length of each rollback trajectory. If a trajectory exceeds the token limit during the rollback phase, its incomplete portion is saved to a replay buffer and processed in subsequent iterations.
Additionally, since rollback worker nodes operate asynchronously, while some nodes handle long trajectories, others can independently process new short rollback tasks.
As shown in Figure 3b, the partial rollout system operates by breaking long responses into multiple segments over several iterations, significantly reducing computational overhead—the system does not need to process the entire response at once but instead processes and stores segments incrementally, generating longer responses while maintaining fast iteration times.
The implementation of partial rollouts also provides a duplicate detection feature. The system can identify duplicate sequences in the generated content and terminate early, reducing unnecessary computation while maintaining output quality.
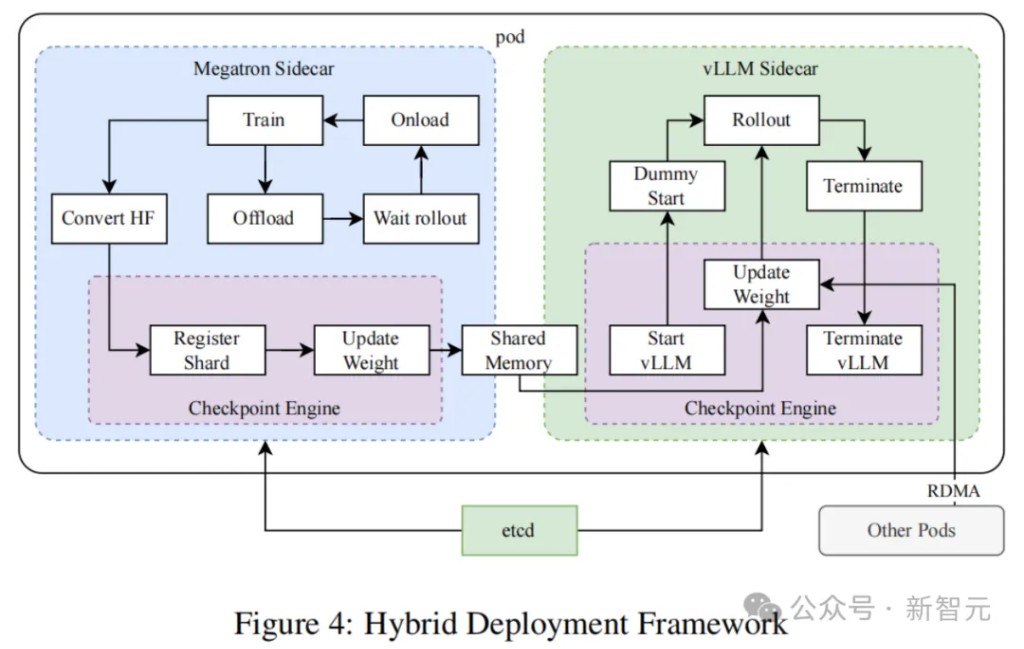
Hybrid Deployment of Training and Inference
Researchers proposed a hybrid deployment strategy for training and inference tasks that utilizes Kubernetes' Sidecar containers to share all available GPUs, co-deploying both tasks within the same Pod. The main advantages of this strategy include:
-
Facilitating efficient sharing and management of resources, avoiding idle states of training nodes waiting for inference nodes (when deployed on different nodes).
-
Allowing training and inference to iterate independently through the use of different deployment images, resulting in better performance
-
The architecture is not limited to vLLM and can easily integrate other frameworks.
As shown in Figure 4, researchers implemented this hybrid deployment framework based on Megatron and vLLM, with a conversion time of less than one minute from training to inference, and about ten seconds for reverse conversion.
Experimental Results
Since k1.5 is a multimodal model, researchers conducted a comprehensive evaluation of various benchmarks across different modalities. The benchmarks mainly include the following three categories:
-
Text Benchmark: MMLU, IF-Eval, CLUEWSC, C-EVAL
-
Reasoning Benchmark: HumanEval-Mul, LiveCodeBench, Codeforces, AIME 2024, MATH500
-
Vision Benchmark: MMMU, MATH-Vision, MathVista
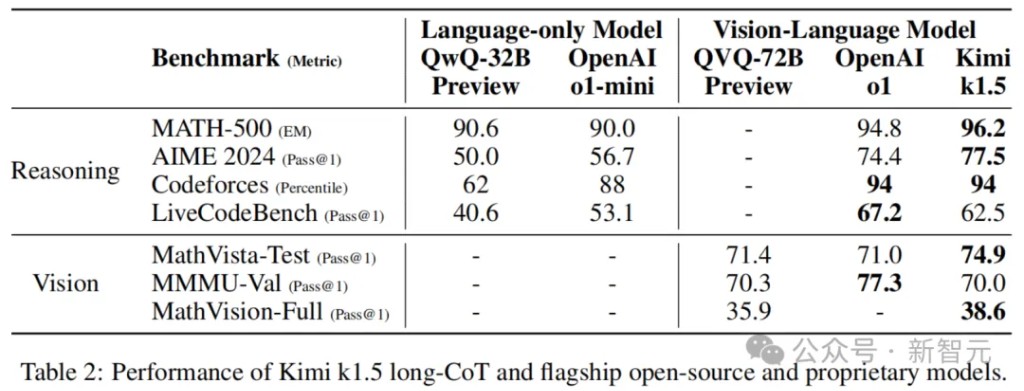
k1.5 Long CoT Model
Kimi's k1.5 Long CoT model achieved significant enhancements in long-distance reasoning through long CoT supervised fine-tuning and visual-text joint reinforcement learning.
Evaluations show that the model has significantly improved reasoning, understanding, and information synthesis capabilities in long contexts, marking a significant advancement in multimodal AI capabilities.
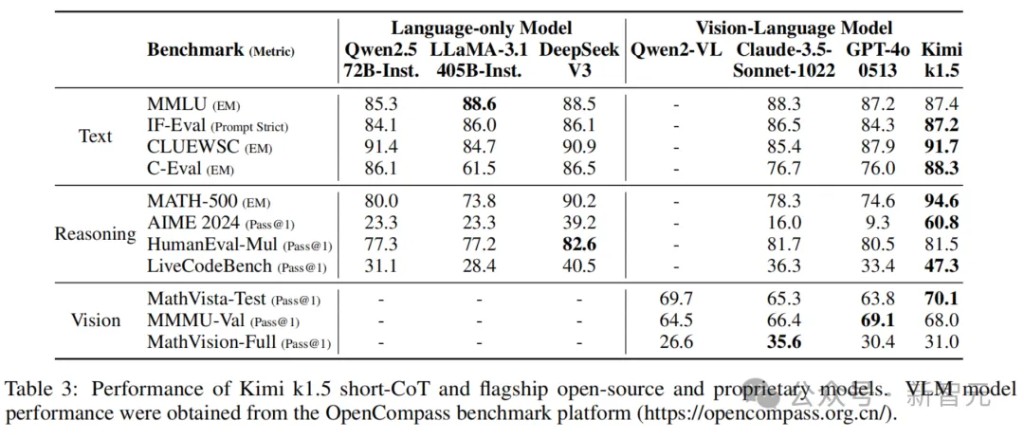
k1.5 Short CoT Model
Kimi's k1.5 Short CoT model integrates various techniques, including traditional supervised fine-tuning methods, reinforcement learning, and long-to-short knowledge distillation.
As shown in Table 3, the k1.5 Short CoT model demonstrates performance comparable to or better than leading open-source and proprietary models across multiple tasks covering various fields.
Long Context Scaling
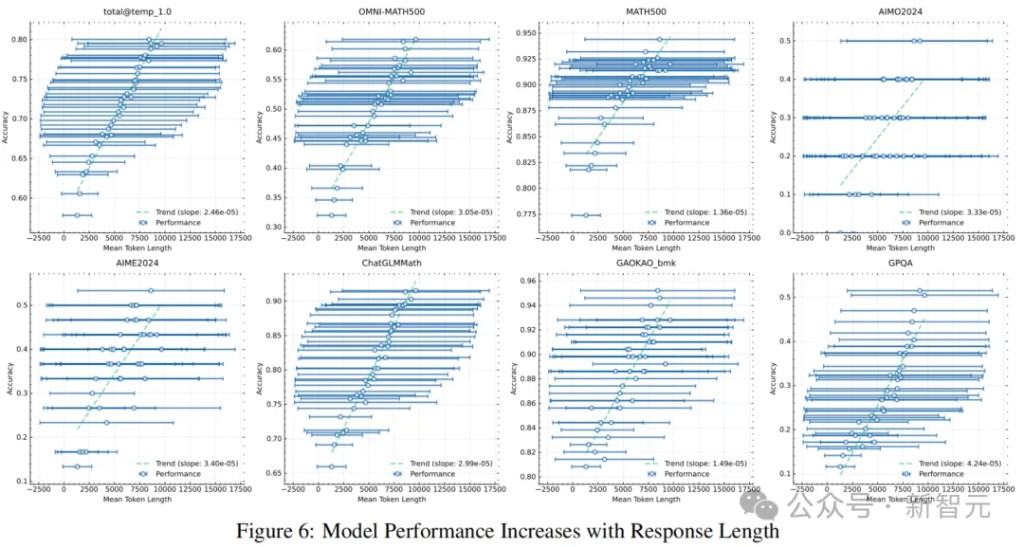
Researchers used a medium-sized model to study the scaling characteristics of reinforcement learning combined with LLM. As shown in Figure 5, as training progresses, both the response length and performance accuracy of the model increase.
Notably, in more challenging benchmark tests, the growth in response length is steeper, indicating that the model learns to generate more detailed solutions when handling complex problems
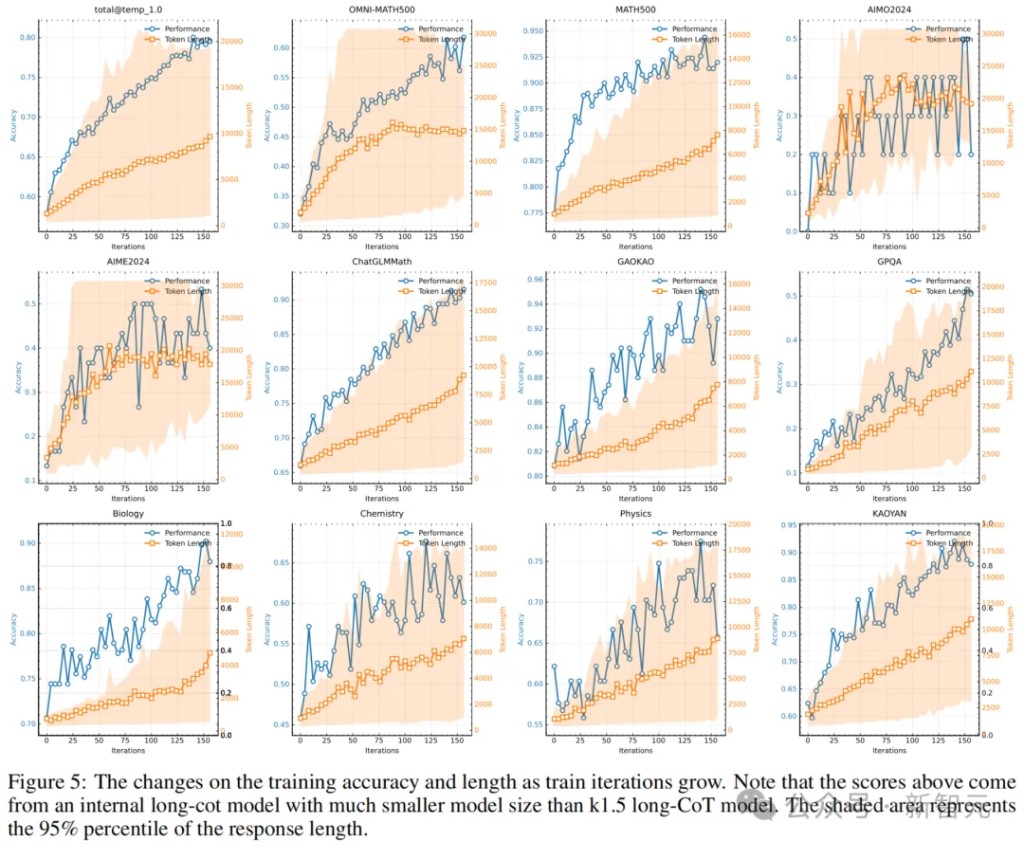
Figure 6 shows a significant correlation between the context length of the model output and its problem-solving ability.
Ultimately, the k1.5 model can support a context length of 128k and continues to achieve improvements in difficult reasoning benchmark tests.
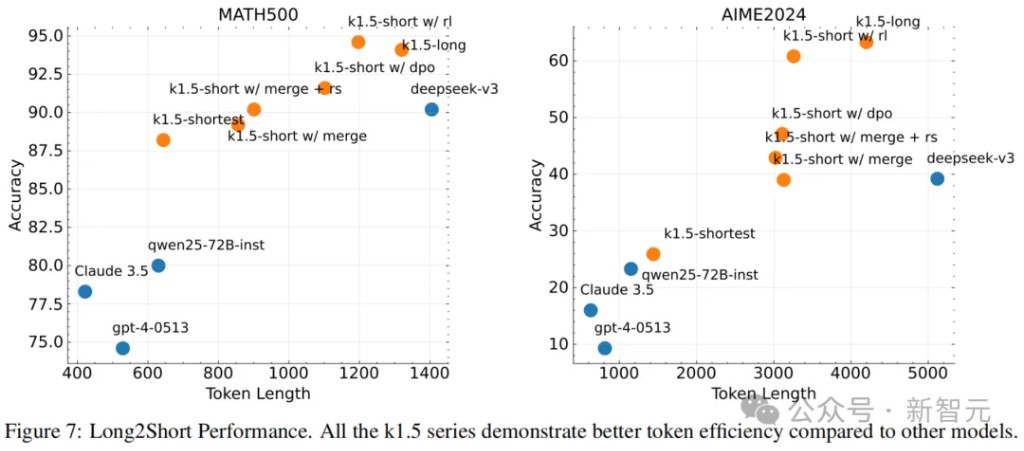
From Long to Short
Researchers focused on the Token efficiency in the long2short problem, particularly how long CoT models enhance the performance of short models.
As shown in Figure 7, the proposed long2short reinforcement learning algorithm outperforms other methods (such as DPO and model merging) in terms of Token efficiency.
Notably, all models in the k1.5 series (marked in orange) outperform other models (marked in blue) in Token efficiency.
Thinking Model, Entering the Sprint
It can be seen that Kimi has made another step forward in the multimodal reasoning technology roadmap.
Starting from November 2024, their first launched mathematical reasoning model K0-math has demonstrated its leading position in the field of mathematics.
A month later, the K1 visual thinking model was born, which not only inherits the mathematical foundation of K0-math but also breakthrough unlocks visual understanding capabilities.
This means that K1 can not only "calculate" but also "see"—by understanding the information in images and deriving answers through step-by-step reasoning.
Now, k1.5 has continued to advance, refreshing the SOTA in multiple fields such as mathematics, physics, chemistry, code, and general use, and can even rival the world's top models.
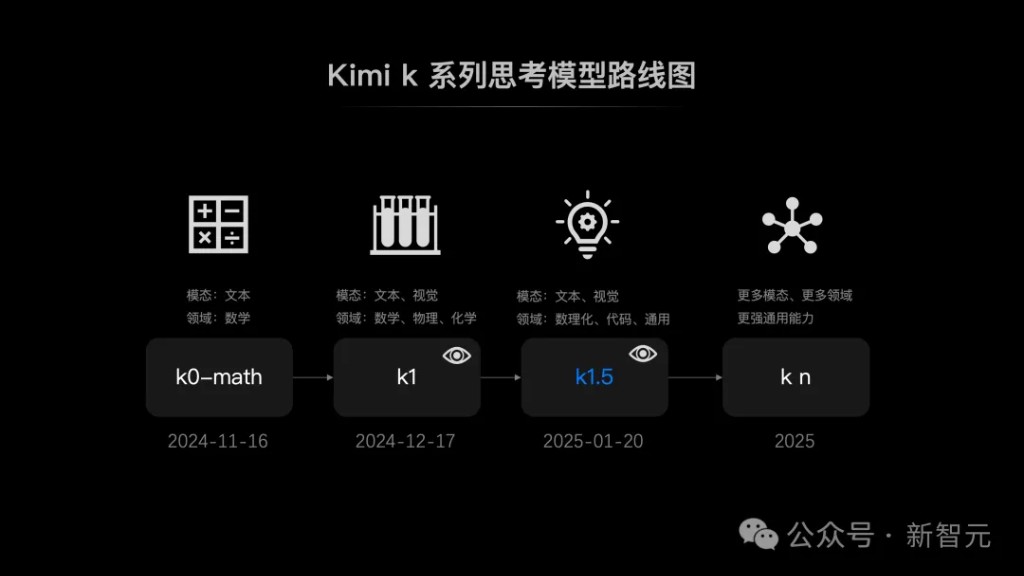
Next, Kimi will continue to focus on multimodal reasoning, iterating to develop the Kn series of models that can operate in more modalities, more fields, and possess stronger general capabilities.
The k1.5 has already brought many surprises, and we are indeed looking forward to the arrival of the next generation of models.
Source: [New Intelligence](https://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2652559712&idx=1&sn=96e8317da6daa85840c54984249a5d01&chksm=f0ac3ab86c4d7a0a140fa0ffa692a37f039ea79747e6e099439c8b2bd56182d76ef5f7e65eee&mpshare=1&scene=23&srcid=0121gHbvR2ACvHdjpUA9KgGV&sharer_shareinfo=c 9bbb41c6765d58ac4ef451338116420&sharer_shareinfo_first=c9bbb41c6765d58ac4ef451338116420#rd), original title: "Kimi Hard Hits the Full Version o1, First Exposes Training Details! A New Paradigm of Reinforcement Learning Scaling is Born"
Risk Warning and Disclaimer
The market has risks, and investment requires caution. This article does not constitute personal investment advice and does not take into account the specific investment goals, financial situation, or needs of individual users. Users should consider whether any opinions, views, or conclusions in this article are suitable for their specific circumstances. Investing based on this is at one's own risk
