
Breakdown of the Largest IPO Financing Project Added to the Sci-Tech Innovation Board This Year: The Initial Exploration of Moore Threads' Commercialization

預計最早 2027 年盈利
“國產 GPU 第一股” 之戰已經打響。
作為 “國產 GPU 四小龍” 的摩爾線程智能科技(北京)股份有限公司(下稱 “摩爾線程”)、沐曦集成電路(上海)股份有限公司(下稱 “沐曦集成”)科創板 IPO 均已先後獲得受理。
同時,GPU 大廠壁仞科技、燧原科技、格蘭菲智能科技股份有限公司則處於 IPO 輔導階段。
這意味着,“國產 GPU 四小龍” 都踏上了資本化之路。
其中摩爾線程無疑是最為受矚的存在。
摩爾線程的核心團隊成員基本來自英偉達,旗下的 MTT S80 顯卡的單精度浮點算力性能接近英偉達 RTX 3060,自建的千卡 GPU 智算集羣效率超過同等規模國外同代系 GPU 集羣。
2024 年,摩爾線程收入已經達到 4.38 億元,同比增長了超 2 倍。
但由於同期研發費用仍達到 13.59 億元,造成的淨虧損仍達到 14.92 億元,但同比已減虧 1 成左右。
摩爾線程計劃募資 80 億元,投向 AI 訓推一體芯片、圖形芯片和 AI SoC 芯片的研發。
這是今年上半年科創板新增 IPO 項目中最大的一筆募資規模。
同期獲得受理的沐曦集成 IPO 募資額只有摩爾線程的一半左右。
誰將成為 “國產 GPU 第一股”,市場正在翹首以待。
新品 “嶄露頭角”?
從產品佈局來看,摩爾線程屬於 “全能型選手”。
品類涵蓋 AI 智算、專業圖形加速、桌面級圖形加速和智能 SoC,可以滿足政府、企業和個人消費者的需求。
AI 智算類產品包括訓練智算卡、推理卡、超節點服務器及誇娥智算集羣等。
該大類產品在 2024 年首度實現零突破,創收 3.36 億元,佔比超過 7 成。
這一方面受益於市場對大模型訓練、推理部署等場景的需求快速增長;
另一方面,這和產品落地時間有關。摩爾線程直到 2023 年才推出可提升 AI 訓練和推理能力的第三代 GPU 芯片,並基於此搭建了千卡集羣智算中心。
目前摩爾線程的代表性產品之一 MTT S4000,正是在 2023 年底推出的訓推一體全功能智算卡。
雖然 MTT S4000 和英偉達的 H100 仍存在較大的差距,但摩爾線程已經對其進行迭代,並在此次招股書中首度披露新品 “MTT S5000” 對標 H100 的粗略數據情況。
摩爾線程稱 MTT S5000 可通過 FP8 精度支持等創新提升性能。
其中,FP(Floating Point)是標準浮點數類型。作為衡量算力性能的指標之一,FP 一般可分為 FP8、FP16、FP32 等,FP 標註數值與精度成正比。
在終端場景的應用中,雖然精度越高會帶來更高的準確性,但同時還會帶來能耗、內存、計算效率的壓力。
理想的目標是保持低精度的同時還能實現準確性、效率、內存、能耗的平衡。
FP8 是目前深度學習領域較為新型的低精度浮點格式之一。雖然 FP8 相較於此前的 FP32 格式精度較低,但部分企業目前通過特殊處理已經可以實現以微小的精度損失換來高效的運算和更低內存佔用。
例如 DeepSeek V3 便引入了 FP8 混合精度訓練框架,首次在超大模型驗證了其有效性。
“通過支持 FP8 計算與存儲,我們既實現了訓練加速,又降低了 GPU 內存佔用。” DeepSeek 團隊在 V3 開源報告中指出,“與 BF16 基線相比,我們 FP8 訓練模型的相對損失誤差始終保持在 0.25% 以下,這個水平完全在訓練隨機性的可接受範圍內。”
不過目前摩爾線程僅披露 MTT S5000 在 FP32 指標中與國際大廠的差異。
MTT S5000 的 FP32 算力性能為 32TFLOPS,高於英偉達 A100 的 19.5TFLOPS,但低於英偉達 H100、AMD 的 MI325X,二者分別為 67TFLOPS、163.4TFLOPS。
儘管 FP32 不是唯一的性能指標,但可以看出 MTT S5000 的算力性能較上一代的 MTT S4000 已有所升級,後者的 FP32 僅為 25TFLOPS。
不僅如此,摩爾線程基於 MTT S5000 還構建了千卡 GPU 智算集羣,效率超過同等規模國外同代系 GPU 集羣。
此番 IPO,摩爾線程的目標之一就是投資 25 億元新建 “新一代自主可控 AI 訓推一體芯片研發項目”,包括引入先進工藝、先進封裝等,預計建設週期為 3 年。
市場期待更多商業化成果可以得到實現。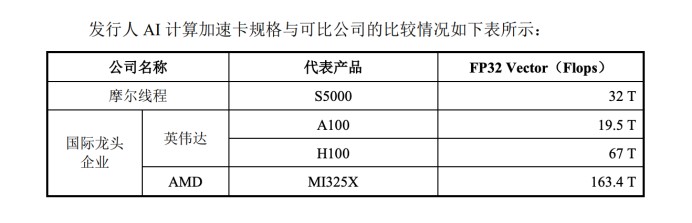
商業策略轉向
儘管品類涵蓋 B 端和 C 端,但摩爾線程目前整體的收入規模仍不敵沐曦集成。
2024 年,摩爾線程 4.38 億元的收入僅為沐曦集成 6 成左右。
這或許和二者的商業化策略差異有關。
摩爾線程聚焦全功能 GPU 產品的開發,即兼具功能完備性與精度完整性。
一方面,摩爾線程的單一 GPU 集成了 AI 計算加速、圖形渲染、物理仿真和科學計算等多種功能;
另一方面,GPU 還支持 FP64、FP32 等不同計算精度,滿足終端場景的個性化需求。
雖然 B 端和 C 端兩手抓,但摩爾線程在開拓 C 端市場上略顯 “吃力”。
摩爾線程推出的 MTT S80/S70 系國內首款消費級 GPU 產品,可以兼容多款遊戲。其中 MTT S80 的 FP32 算力性能接近英偉達的 RTX 3060。
但 2022 年至 2024 年,包括 MTT S80/S70 等消費級 GPU 等在內的桌面級圖形加速產品收入合計僅為 0.72 億元。
不僅如此,由於這類產品市場競爭激烈,導致摩爾線程不得不採取低價策略——2023 年、2024 年單價分別僅為 537.52 元、884.61 元。
這甚至無法覆蓋成本。同期毛利率分別為-103.74%、-15.87%。
“桌面級圖形加速產品毛利率為負,主要由於中低端市場面臨國際品牌的激烈競爭,導致公司產品銷售價格存在一定壓力。” 摩爾線程指出。
相比之下,沐曦集成的 GPU 主要聚焦市場增長較快的人工智能訓練和推理、通用計算與圖形渲染領域,集中在 B 端市場,商業化成果兑現較快。
面對商業化進展遲緩的消費級產品,摩爾線程正在轉變自己的策略,更加聚焦於專業圖形加速、AI 智算的 B 端產品。
“面對國際知名公司的成熟產品,公司芯片、板卡產品銷售價格存在一定壓力。隨着產品不斷發展,公司逐步拓展專業圖形加速、AI 智算等高性能、高毛利領域產品,毛利率逐漸上升。” 摩爾線程指出。
摩爾線程在專業圖形加速、AI 智算領域確實能夠斬獲更為可觀的毛利,2024 年 AI 智算、專業圖形加速的板卡毛利率分別高達 90.7%、83.13%。
同期,沐曦集成的訓推一體、智算推理的板卡毛利率則分別為 63.5%、10.09%。
隨着商業策略的轉變,摩爾線程有望迎來扭虧時刻。目前管理層預計最早可在 2027 年實現盈利。
已披露金額的在手訂單中,摩爾線程已有 4.4 億元銷售合同正在履行中。
市場期待摩爾線程能夠早日在終端市場佔有一席之地。
