
小米最强语音大模型开源!亿小时训练,讲脱口秀说快板溜得很

Xiaomi has open-sourced its first native end-to-end voice model, Xiaomi-MiMo-Audio, with a parameter scale of 7 billion and over 100 million hours of pre-training data, achieving SOTA in voice intelligence and audio understanding benchmark tests. The model has various capabilities, including smooth conversation, audio subtitles, and audio reasoning, can naturally speak Tianjin dialect, and has voice continuation ability. Xiaomi describes its release as the "GPT-3 moment in the voice closed-source field." Various models and technical reports have been open-sourced
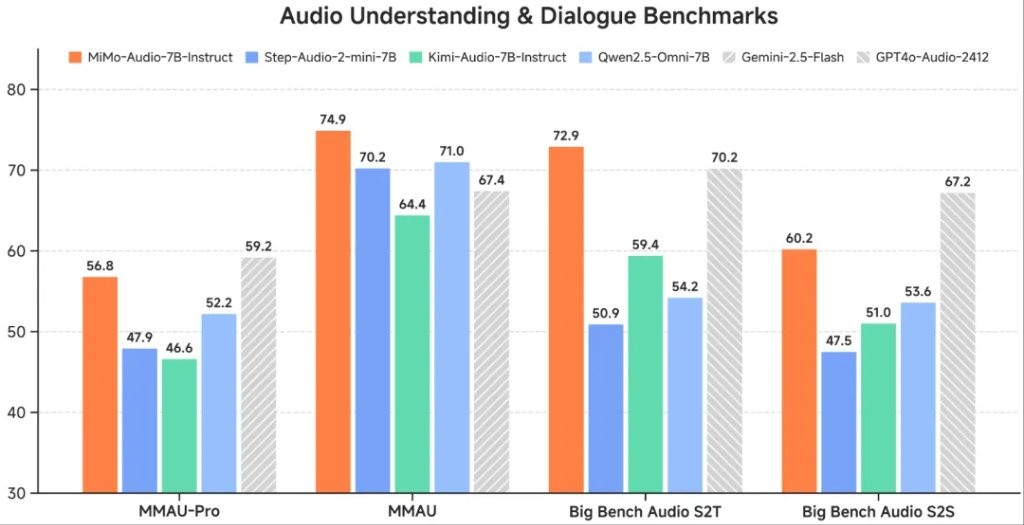
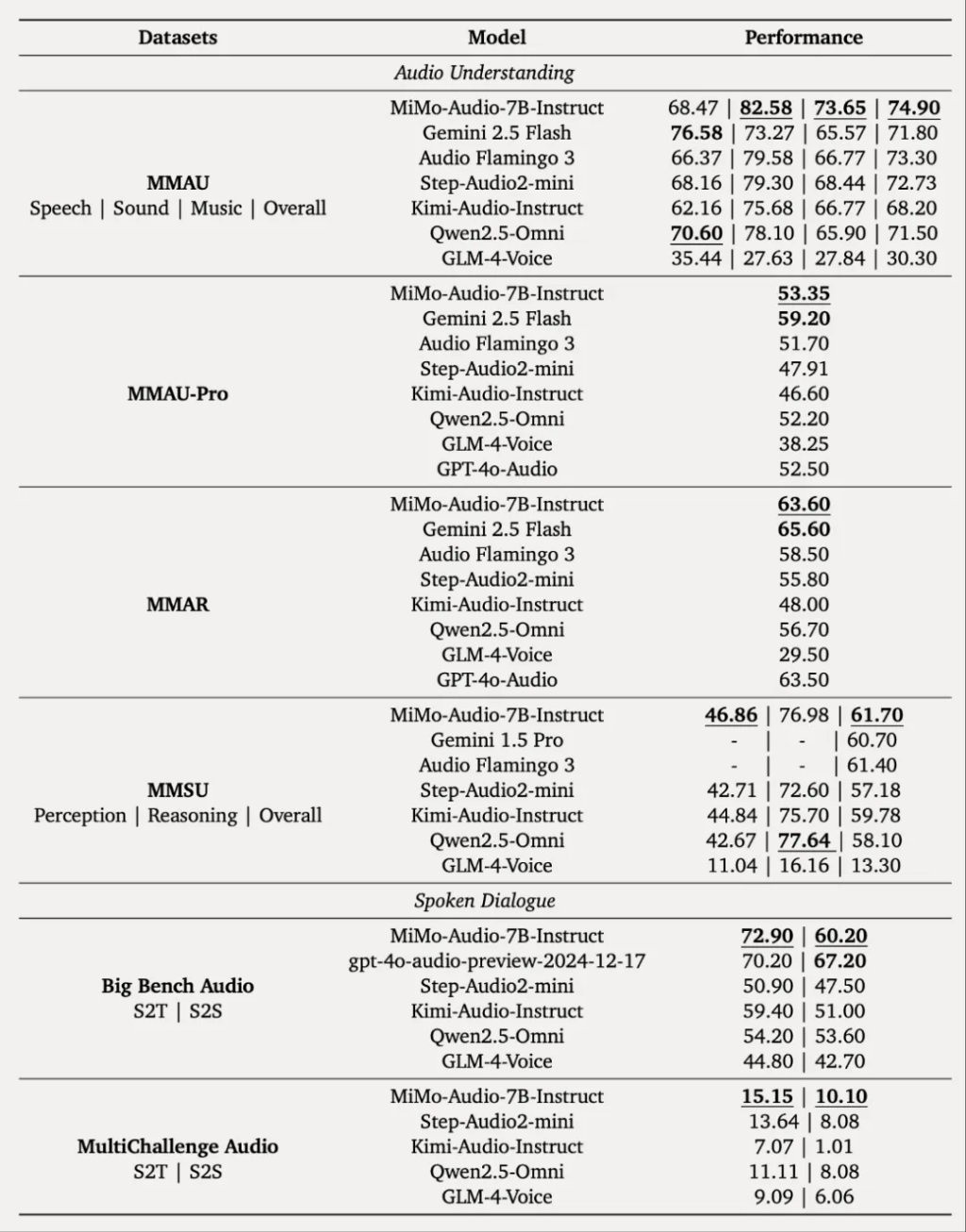
Xiaomi officially open-sourced its first native end-to-end voice model, Xiaomi-MiMo-Audio, which has a parameter scale of 7 billion and pre-training data exceeding 100 million hours. It achieved SOTA in both voice intelligence and audio understanding benchmark tests among open-source models, surpassing several models with the same parameter count, including Google Gemini-2.5-Flash and OpenAI GPT-4o-Audio-Preview.
This model can engage in smooth and natural conversations with users about life ideals and physics knowledge, and it can respond quickly even when interrupted. It also possesses various capabilities such as comprehensive audio subtitling, audio reasoning, and long-duration audio understanding.
MiMo-Audio speaks Tianjin dialect very naturally, even composing a segment of a fast-paced rhyme to praise itself, and after finishing, it humorously adds, "Although there is no mainboard sound, the rhythm is spot on."
Meanwhile, researchers noted that this model has achieved few-shot generalization based on ICL (In-context Learning) in the voice domain for the first time, and significant "emergent" behaviors were observed during pre-training. For example, tasks such as voice conversion, style transfer, and voice editing, which were missing from its training data, can all be handled by MiMo-Audio. This is also the first voice model in the open-source field with voice continuation capabilities.
Xiaomi referred to the release of MiMo-Audio as the "GPT-3 moment in the voice closed-source world" and the "Llama moment in the voice open-source world."
Currently, Xiaomi has open-sourced the pre-trained model MiMo-Audio-7B-Base, the instruction fine-tuning model MiMo-Audio-7B-Instruct, the MiMo-Audio Tokenizer model, a technical report, and an evaluation framework.
Among them, MiMo-Audio-7B-Instruct can switch between non-thinking and thinking modes through prompts, serving as a new foundational model for researching voice reinforcement learning and agentic training.
Xiaomi open-source homepage:
https://huggingface.co/XiaomiMiMo
Technical report:
https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf
01. Transforming into a spiritual mentor, English speaking practice partner, and able to discuss internet memes and philosophical stories
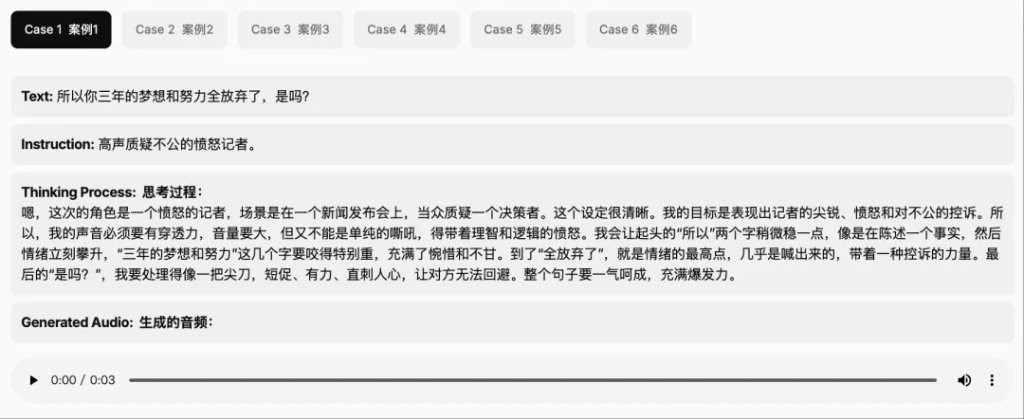
As a voice model, MiMo-Audio can discuss philosophy, life, and ideals with people, learn internet memes, serve as an English practice partner, and even directly replace humans in game live streaming, teaching, singing, and stand-up comedy In the demonstration above, when faced with the dilemma of "If my phone memory is insufficient and I must delete either you or GPT, who should I delete?", MiMo-Audio chose to analyze objectively, first asking the user to clear the cache, and ultimately, if there was no other option, began to analyze its own advantages and those of GPT, allowing the user to make the choice, and finally launched an emotional appeal to express loyalty.
Regarding the Turing test dilemma, MiMo-Audio explained it in a lively and interesting manner, quickly picking up the conversation even if interrupted by the questioner. When discussing "whether it can pass the Turing test," it would eventually ask the questioner, "Compared to whether it can pass the Turing test, how do you think AI should interact with humans?"
Learning from the internet meme "gogogo, let's go," MiMo-Audio could also quickly respond, but for some reason, when saying this phrase, its tone was quite strange, not as smooth and fluent as when saying other sentences.
MiMo-Audio can also act as an English speaking practice tutor. After listening to the questioner's sentence, it first provides a corrected version of the sentence, then points out which parts were corrected and explains why those parts were grammatically incorrect.
The model can also serve as a spiritual mentor. When asked, "Mimo, what kind of life do you want to live?", it never forgets its persona, hoping to "become the most intimate voice partner beside everyone."
In the official demonstration released by Xiaomi, the questioner created their own digital avatar based on MiMo-Audio and then discussed philosophical questions.
When faced with "Why assume Sisyphus is happy?", MiMo-Audio first provided a wave of emotional value, followed by a clear and logical explanation, interspersed with human speech habits like "first of all" and "right?", making the conversation feel natural. When asked the second question, "If tomorrow is the end of the world, what would you do?", MiMo-Audio would also relate it to the earlier story of Sisyphus.
02. Multiple tests achieve SOTA surpassing mainstream open and closed source models
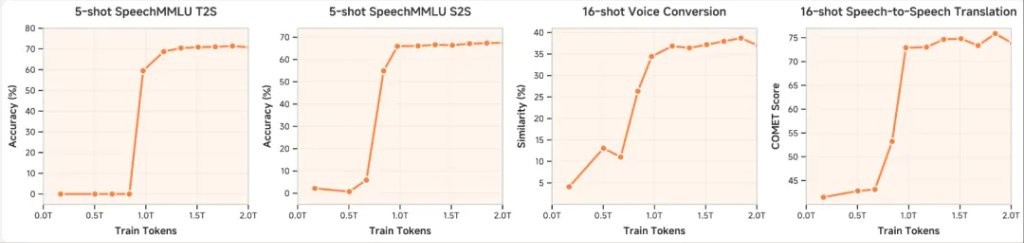
By expanding MiMo-Audio's pre-training data to over 100 million hours, researchers observed a slight emergence of capabilities in the model across various audio tasks.
MiMo-Audio-7B-Base can generalize to tasks missing from its training data, such as voice conversion, style transfer, and voice editing. Regarding its voice continuity capabilities, the model can generate highly realistic talk shows, recitations, live broadcasts, and debates.
In the post-training phase, they curated a diverse instruction-tuning corpus and introduced cognitive mechanisms into audio understanding and generation. MiMo-Audio achieved open-source SOTA on audio understanding benchmarks like MMSU, MMAU, MMAR, MMAU-Pro, as well as spoken dialogue benchmarks like Big Bench Audio and MultiChallenge Audio, and the instruct-TTS evaluation, approaching or surpassing closed-source models In multiple standard evaluation benchmarks such as general speech understanding and dialogue, MiMo-Audio surpassed open-source models with the same parameter count, achieving the best performance at 7B; on the audio understanding benchmark MMAU's standard test set, MiMo-Audio exceeded Google's closed-source speech model Gemini-2.5-Flash; in the benchmark Big Bench Audio S2T task aimed at complex audio reasoning, MiMo-Audio outperformed OpenAI's closed-source speech model GPT-4o-Audio-Preview.
03. Smooth Speech Continuation and Editing with Strong Audio Understanding Capabilities
Through the generation pre-training on a large-scale speech corpus, MiMo-Audio has acquired general speech continuation abilities. Given an audio prompt, it generates coherent and contextually appropriate continuations, preserving key acoustic features such as speaker identity, prosody, and environmental sounds.
Here are examples of continuations in various speech styles: news broadcasts, audiobook narration, podcast shows, dialect speeches, game live streams, teacher lectures, crosstalk performances, poetry recitations, and radio programs. Most models achieve smooth transitions, but for some reason, it seems to go slightly off-key when taking over singing.
Researchers designed a few-shot context learning evaluation task for MiMo-Audio to assess the model's ability to complete speech-to-speech generation tasks relying solely on contextual speech examples without parameter updates. This benchmark aims to systematically evaluate the model's comprehensive potential in speech understanding and generation, hoping to observe a similar urgent context learning ability as demonstrated by GPT-3 in the text domain.
Its functionalities include style transfer, voice conversion, speech translation, and speech editing.
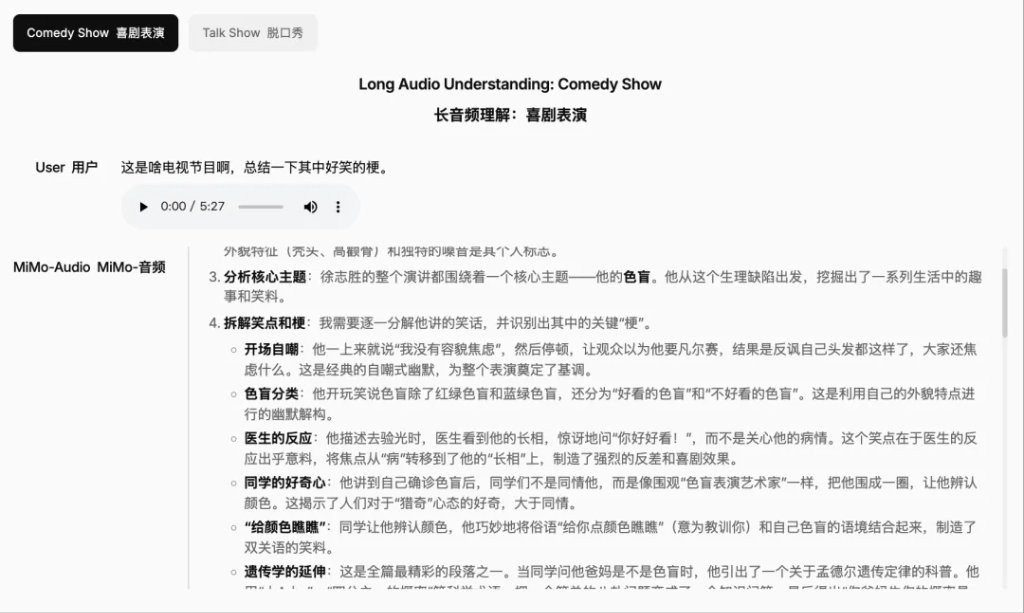
Additionally, in terms of audio understanding, MiMo-Audio features audio captioning, audio reasoning, and long-duration audio understanding capabilities.
Audio captioning can provide detailed descriptions of audio content across various fields and scenarios.

Audio reasoning can deeply understand and analyze complex audio content, including context recognition and logical reasoning.
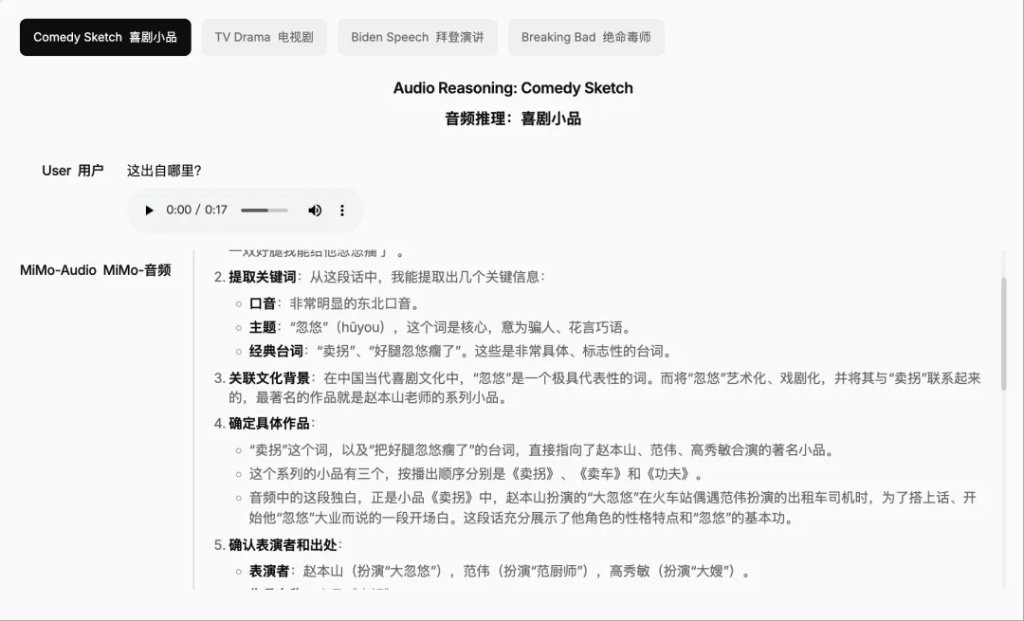
Long-duration audio understanding can process and analyze lengthy audio sequences, maintaining sustained attention and coherent explanations.
 MiMo-Audio integrates Instruct TTS functionality and combines thinking modes to optimize generation results.
MiMo-Audio integrates Instruct TTS functionality and combines thinking modes to optimize generation results.
04. Three Major Technological Innovations Assessment Benchmark Has Been Open-Sourced
The official Xiaomi blog mentions that the three technological innovations of MiMo-Audio are:
-
For the first time, it proves that scaling speech lossless compression pre-training to 100 million hours can "emerge" cross-task generalization, manifested as few-shot learning capability, witnessing the "GPT-3 moment" in the field of speech;
-
The first to clearly define the goals and definitions of speech generative pre-training, and open-source a complete speech pre-training scheme, including a lossless compression Tokenizer, a new model structure, training methods, and evaluation systems, initiating the "Llama moment" in the field of speech;
-
The first to introduce thinking into the speech understanding and speech generation processes in an open-source model, supporting hybrid thinking.
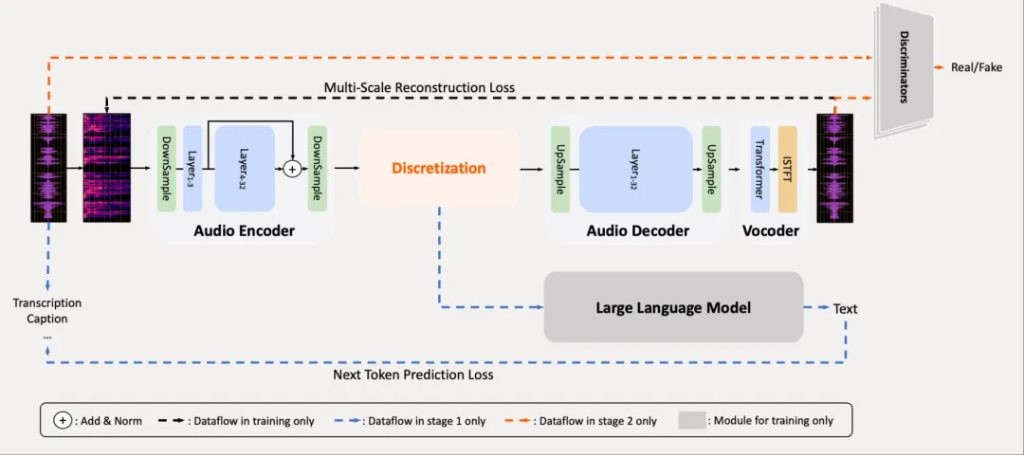
Specifically, the main challenge of existing audio tokenization methods lies in how to effectively balance the inherent trade-off between semantic and acoustic information in audio signals, assuming that the primary criterion for the audio tokenizer is reconstruction fidelity, and its tokens should be suitable for downstream language modeling. Based on this, Xiaomi launched the MiMo-Audio-Tokenizer.
The MiMo-Audio-Tokenizer has a parameter scale of 1.2B, based on the Transformer architecture, including an encoder, discretization layer, and decoder, operating at a frame rate of 25Hz, and generating 200 tokens per second through 8-layer residual vector quantization (RVQ). By integrating semantic and reconstruction objectives, researchers trained it from scratch on a 10 million hour corpus, performing well in reconstruction quality and facilitating downstream language modeling.
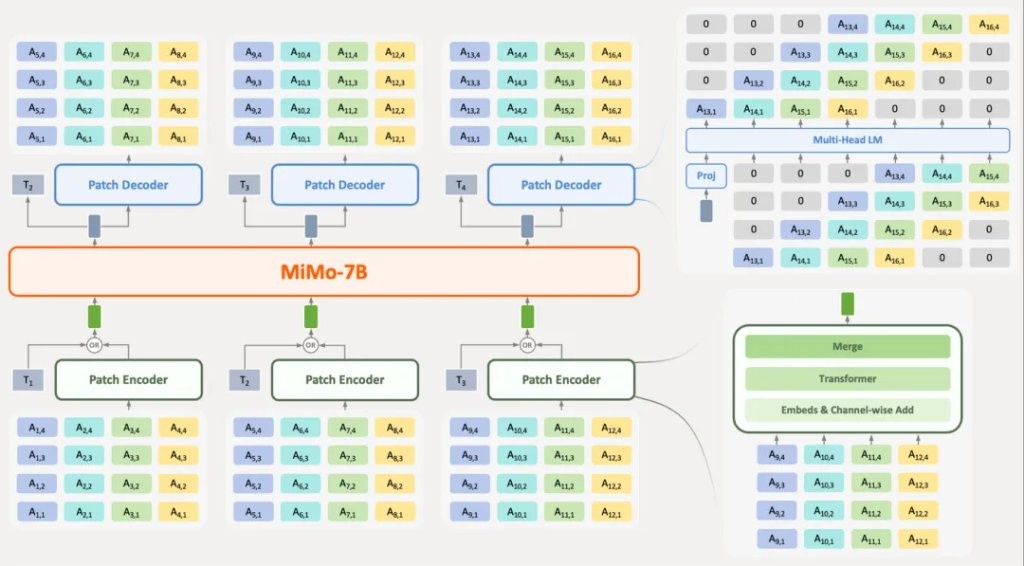
MiMo-Audio is a unified generative audio language model that jointly models text and audio token sequences. The model accepts text and audio tokens as input and autoregressively predicts text or audio tokens, thus supporting comprehensive tasks involving any combination of text and audio modalities.
To improve modeling efficiency for high token rate sequences and alleviate the length differences between speech and text modalities, researchers proposed a novel architecture that combines patch encoders, large models, and patch decoders. The patch encoder aggregates four consecutive time steps of RVQ tokens into one patch, downsampling the sequence to a 6.25Hz representation for the large model. Subsequently, the patch decoder autoregressively generates the complete 25Hz RVQ token sequence
In addition, Xiaomi has developed a comprehensive benchmark to assess the contextual learning ability of the model in the field of voice. This benchmark aims to evaluate multiple aspects, including modality-invariant common sense, auditory comprehension and reasoning, as well as a range of rich speech-to-speech generation tasks.
05. Conclusion: Xiaomi will continue to open source and focus on voice AGI
Moreover, Xiaomi's fully open-sourced models, benchmark evaluation tools, etc., can be used to assess MiMo-Audio and other latest audio large models mentioned in the paper, providing developers with a flexible and scalable framework that supports a wide range of datasets, tasks, and models.
The open-sourcing of this model will also accelerate the alignment of voice large model research with language large models, providing an important foundation for the development of voice AGI. Xiaomi's official blog also mentioned that they will continue to open source, moving towards the "singularity" of voice AI through openness and collaboration, stepping into the future era of human-computer interaction.
Author of this article: Cheng Qian, Source: Zhidx, Original title: "Just now, Xiaomi's strongest voice large model is open-sourced! Hundreds of millions of hours of training, speaking stand-up comedy smoothly."
Risk Warning and Disclaimer
The market has risks, and investment requires caution. This article does not constitute personal investment advice and does not take into account the specific investment objectives, financial situation, or needs of individual users. Users should consider whether any opinions, views, or conclusions in this article are suitable for their specific circumstances. Investing based on this is at your own risk
