
Musk's retweet of Kimi's paper sparked a big discussion in Silicon Valley, what is the next battlefield for Attention?
馬斯克轉發了 Kimi 團隊的論文《Attention Residuals》,引發硅谷熱議,Karpathy 和前 OpenAI 聯合創始人 Jerry Tworek 對此發表看法。與此同時,字節跳動 Seed 團隊與華中科技大學聯合發佈了另一篇相關論文《Mixture-of-Depths Attention》,南京大學等人的論文《When Does Sparsity Mitigate the Curse of Depth in LLMs》也在同周發佈。這三篇論文集中探討了注意力機制的結構性問題,標誌着該領域的重大進展。
2026 年 3 月 16 日,Kimi 團隊把一篇叫 Attention Residuals 的論文掛上了 arXiv,然後事情迅速失控。馬斯克轉發了,Karpathy 評了一句"我們還沒有真正把 Attention is All You Need 的標題當回事",前 OpenAI 聯合創始人 Jerry Tworek 直接給了四個字,deep learning 2.0。一篇來自中國團隊的架構論文能在硅谷引起這種級別的討論,上一次可能要追溯到 DeepSeek-V3。
但熱鬧歸熱鬧,大多數討論停留在"Kimi 搞了個新東西,大佬們很興奮"的層面。被忽略的是,同一天,字節跳動 Seed 團隊和華中科技大學聯合發了另一篇論文,叫 Mixture-of-Depths Attention(MoDA),解決的是完全相同的問題,用的是完全不同的路線。同一周內,南京大學 Dilxat Muhtar、MPI Shiwei Liu 等人的第三篇論文"When Does Sparsity Mitigate the Curse of Depth in LLMs"從理論側給出了最精確的病理報告。
三篇論文密集出現,對準的是同一個靶子。這不是巧合。一個被忽視了近十年的結構性問題,終於到了不得不解決的臨界點。
問題不在注意力的序列維度上。注意力在過去幾年已經進化了很多代,從多頭注意力到分組查詢注意力,到 DeepSeek 的 MLA,到各種稀疏變體,每一代都在優化 token 與 token 之間怎麼互相看。這場軍備競賽足夠精彩,但它遮蔽了一個事實——層與層之間的信息傳遞方式,從 2017 年 Transformer 論文發表至今,答案一直是同一個。殘差連接,h = h + f(h),一個不帶任何學習參數的加法操作。
所有歷史層的輸出等權求和。沒有選擇,沒有遺忘,沒有學習。每一層的貢獻被一視同仁地堆進殘差流裏,不管它學到的是關鍵特徵還是噪音。
殘差連接是深度學習歷史上最成功的"臨時方案"。
最成功的臨時方案
殘差連接是 2015 年何愷明在 ResNet 裏提出的。思路極其樸素,網絡堆到二十幾層就訓不動了,梯度消失讓深層參數幾乎不更新,那就給每一層加一條"高速公路",讓輸入直接跳過這一層接到輸出上。即使這一層什麼都沒學到,信息和梯度至少能通過這條捷徑傳下去。效果立竿見影,ResNet 把網絡從二十幾層推到了一百多層。兩年後 Transformer 問世,殘差連接被原封不動地搬過來。從那以後,這個設計就沒人動過。
不是沒人試過。ReZero、FixUp、Highway Network 都做過變體,讓殘差權重可學習。但沒有一個進入主流大模型的架構選型,因為殘差連接太好用了。簡單、穩定、幾乎不增加計算開銷,在當時的模型規模下,副作用還沒有暴露。
44% 的層在空轉
副作用是什麼?2025 年初,西湖大學、Emory 和 MPI 的 Shiwei Liu 團隊發表了"The Curse of Depth",今年 3 月南京大學 Dilxat Muhtar 等人的"When Does Sparsity Mitigate the Curse of Depth in LLMs"進一步給出了定量診斷,在當前主流大模型的架構下,深層的變換越來越接近恆等映射。輸入什麼就輸出什麼,這一層等於沒有。
數字很難看。研究者用"有用性分數"來衡量每一層是否在做有意義的變換。12 層的模型,所有層都在幹活。16 層,三層廢了。24 層,九層廢了。32 層,14 層廢了,44% 的層幾乎什麼都沒學到。參數量從 9 億增加到 23 億,多花了 156% 的預算,有效層只從 12 增加到 18。
深度詛咒的定量診斷——有效層數隨模型規模增長的效率遞減
原因和殘差連接的工作方式直接相關。每一層的輸出通過殘差連接加到一條"主幹道"上。隨着層數增加,主幹道上累積的信號越來越大(可以理解為"背景音量"不斷升高),但每一層新產生的信號幅度是有限的。到了深層,新信號就淹沒在背景噪音裏了,輸入和輸出幾乎一樣,這一層形同虛設。
殘差連接解決了"讓梯度傳過去"的問題,但製造了"讓深層有意義"的問題。
在大模型時代,這個代價是真金白銀。一層就是幾十億次浮點運算。一個 128 層的模型如果有 44% 的層在空轉,將近六十層的算力在做無用功。社區捲了幾年的推理效率優化,量化、蒸餾、剪枝、稀疏注意力、KV cache 壓縮,全都在優化那些"有用的計算"。
最大的效率黑洞不在注意力的二次方複雜度上,而在一個從 2015 年就沒變過的加法操作上。
給注意力加上深度維度
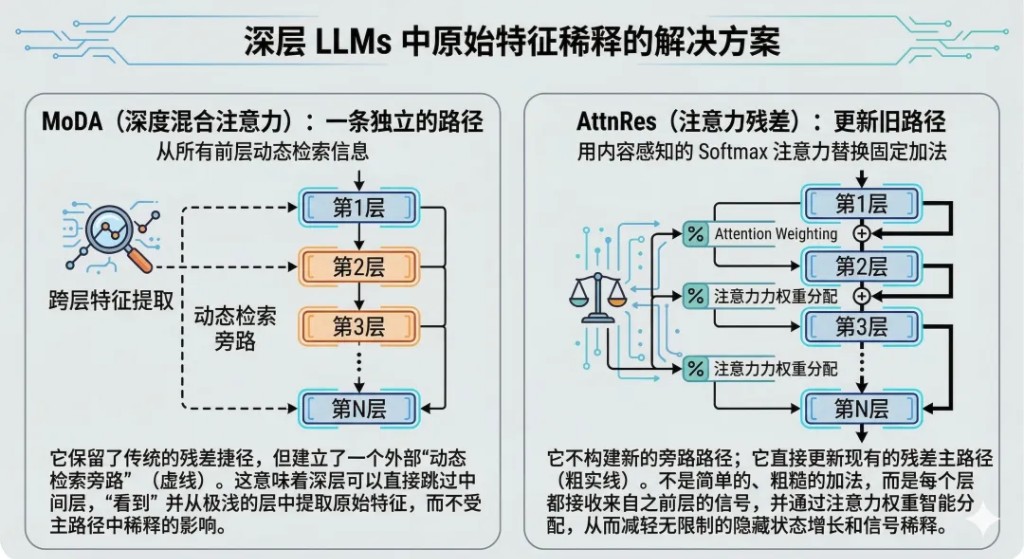
字節 Seed 團隊的 MoDA 選了一條不同的路。它沒有動殘差連接,而是給注意力機制本身加了第二個維度。
標準 Transformer 的注意力只在序列維度上操作,即,當前層的每個 token 去看同層其他 token 的 KV。MoDA 的改動很直覺,把歷史層的 KV 也放進注意力的候選集。一個 token 在第 L 層做注意力計算時,不僅能看到同層的其他 token,還能直接回看第 1 層到第 L-1 層的 KV。序列維度和深度維度在同一個 Softmax 下聯合歸一化。
想法不難理解,難的是怎麼在不拖垮速度的情況下把它做出來。
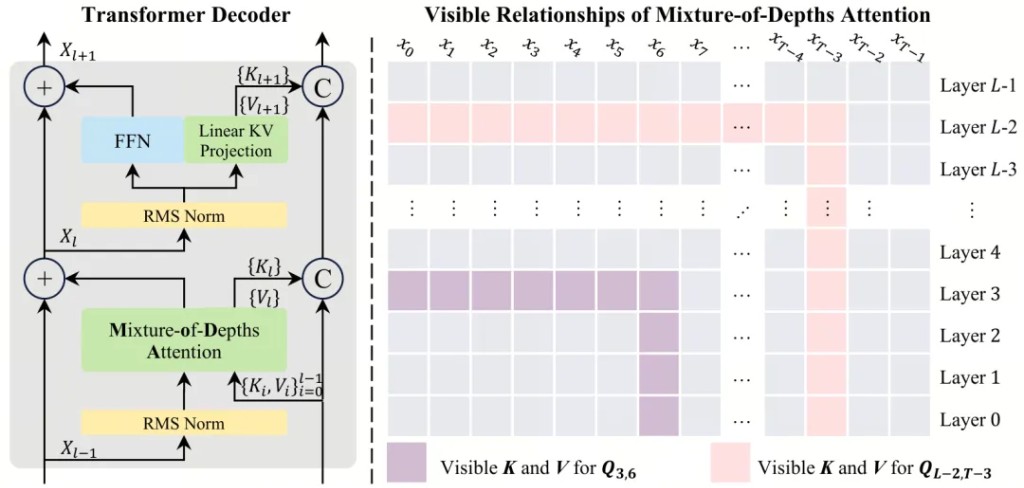
MoDA 的雙維注意力機制——序列維度與深度維度在同一個 Softmax 下聯合歸一化
把所有歷史層的 KV 全塞進注意力,計算量會爆炸。一個 32 層的模型,第 32 層要看前 31 層的所有 KV,等效序列長度直接擴大 32 倍。MoDA 的工程核心是一套"分組重排"策略,只選一部分歷史層的 KV,按組重新排列到連續顯存上,讓 GPU 的矩陣乘法能高效執行。
具體來説,MoDA 引入了"深度流"機制。不是每一層都去看所有歷史層,而是通過一個可學習的路由選出最相關的幾層。這和 Mixture-of-Experts 的思路類似——不是把所有專家都激活,而是動態地選擇需要的專家。區別在於這裏的"專家"是不同深度的歷史層。
在 64K 序列長度下,MoDA 的算子效率達到了 FlashAttention-2 的 97.3%。加了整個深度注意力機制,速度只慢了不到 3%。

分組重排策略——把散落在顯存各處的歷史層 KV 搬運到連續內存區域
在 1.5B 參數的模型上(基於 OLMo2 的訓練配方),MoDA 在 10 個下游任務上的平均性能提升了 2.11%,額外計算開銷僅 3.7%。初看不大,但這是架構層面的改進,不是靠更多數據或更長訓練換來的。而且 MoDA 的效果隨模型規模增大而增強——在更大的模型上,深度退化更嚴重,MoDA 的修復作用更明顯。

MoDA 在 10 個下游任務上的性能對比
更有意思的是 MoDA 和 Post-Norm 的化學反應。主流大模型幾乎全用 Pre-Norm(先歸一化再做注意力),因為 Post-Norm(先做注意力再歸一化)雖然理論上更優,但訓練不穩定。MoDA 的深度 KV 機制恰好給 Post-Norm 提供了額外的梯度通道,Post-Norm 本來的不穩定問題就不再是致命傷了。
MoDA+Post-Norm 的組合打開的可能性是,過去為了訓練穩定而做出的妥協(用 Pre-Norm),也許可以被收回了。
Pre-Norm vs Post-Norm 在加入深度 KV 後的驗證損失差異
不開新路,翻修舊路
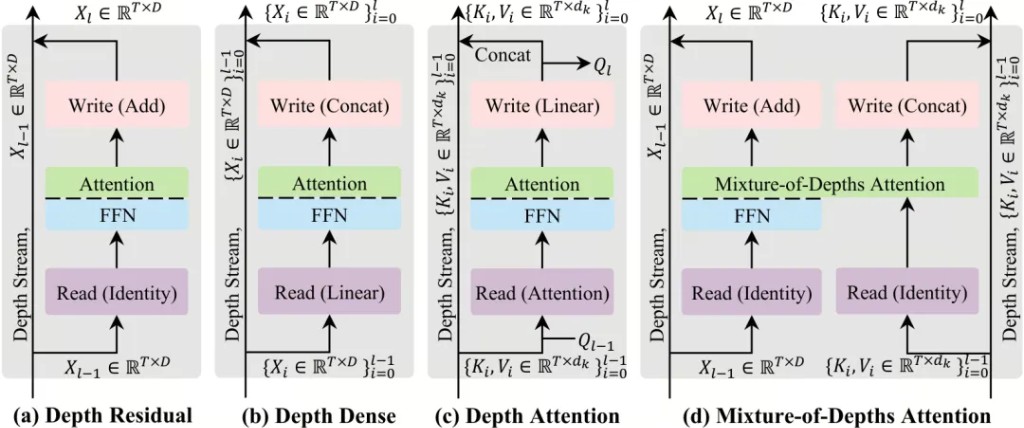
MoDA 沒動殘差連接,它選擇在殘差之外另開一條路。同一天,Kimi 團隊發的 Attention Residuals(AttnRes)走了一條更直接的路線,直接對殘差連接本身動手。
標準殘差連接做的事很簡單,把前面所有層的輸出等權相加,堆進主幹道。沒有選擇,沒有遺忘。AttnRes 把這個固定的等權加法替換成一個注意力操作,每一層用自己的狀態作為查詢,前面所有層的輸出作為候選,用注意力來決定,前面哪些層的特徵對當前層有用,權重各是多少。
殘差連接從一個固定公式變成了一個可學習的動態路由。
AttnRes 的核心思路——用注意力替代等權殘差加法
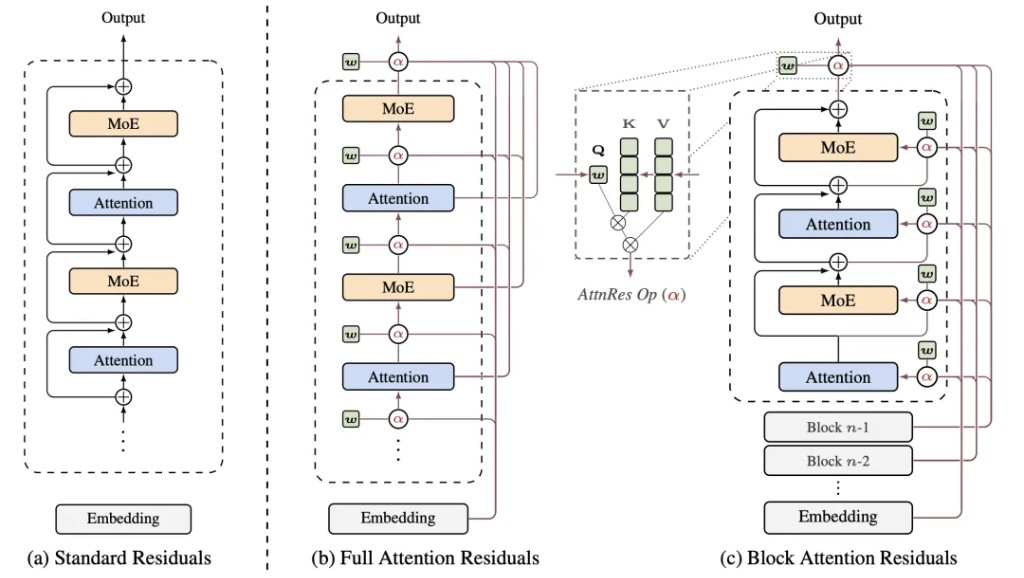
代價是每一層都要額外跑一次深度注意力計算,開銷不低。Kimi 團隊用分塊策略(Block AttnRes)控制成本,把層分成若干個塊,塊內做完整的深度注意力,塊與塊之間只關注塊級別的聚合表徵。
AttnRes 已經被集成進了 Kimi Linear(480 億總參數 / 30 億激活參數),在 1.4 萬億 token 上做了預訓練,效果確認在不同模型規模下一致。這篇論文已經被廣泛報道過,技術細節不再展開。值得放在這裏講的原因是它和 MoDA 的路線對比。

AttnRes 的訓練曲線與消融實驗
兩條路線診斷的病因完全一致,即,深層拿到的淺層信息被殘差更新反覆稀釋了。但下刀的地方不同。MoDA 沒碰殘差連接,而是給注意力加了一個深度維度,讓深層能繞過殘差流直接取淺層的原始特徵。AttnRes 直接對殘差連接開刀,把等權加法換成了注意力加權。一個是"另修一條路",一個是"把原來那條路翻新"。
兩篇論文同一天出現,路線不同,靶子相同。這不是巧合。注意力的深度問題已經是研究社區的共識,區別只在於從哪個方向切入。
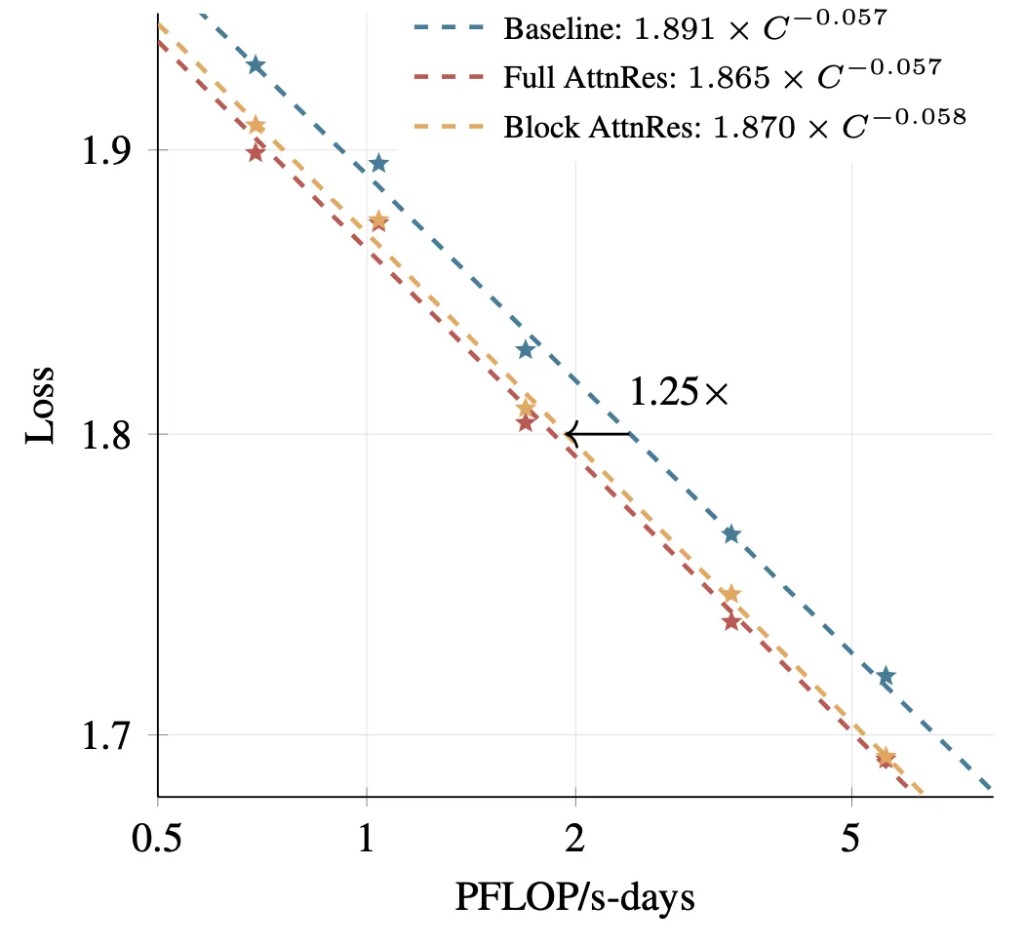
AttnRes 在不同模型規模下的效果一致性
忘了拆的腳手架
回到最開始的問題,為什麼深層空轉這個問題到 2026 年才被認真對待?
因為殘差連接太好用了。它解決了一個當時最緊迫的問題(梯度消失),代價可控(深層退化在小模型上不明顯),替代方案不成熟(ReZero、Highway Network 都沒有經受過大規模驗證)。沒有人有動力去動它。它不是被有意保留的設計選擇,而是被遺忘的臨時方案。當初搭的腳手架,蓋完樓忘了拆,時間一長大家以為它是承重牆。
殘差連接的信號稀釋效應——層數越深,新信號越難被聽見
但真正讓這個問題難以被發現的,不是殘差連接本身,而是注意力機制長期以來只在一個維度上運作。過去八年,注意力的所有進化——多頭、分組查詢、稀疏、線性——都是在序列維度上做文章。token 和 token 之間怎麼互相看,這件事被優化了無數遍。但層和層之間怎麼互相看?這個問題根本沒人問過。深度維度是注意力的盲區。
MoDA 和 AttnRes 從不同方向把這個盲區打開了。MoDA 給注意力加了第二個維度,讓它能同時在序列和深度方向上運作。AttnRes 把層間信息傳遞本身變成了一個注意力操作。路線不同,但共同指向同一個結論,即,注意力不該只看水平方向,它也應該看垂直方向。
這個結論的延伸比兩篇論文本身更大。Transformer 裏還有很多隻在單一維度上運作的固定機制。每一層必須按順序執行,不能跳過。每個注意力頭獨立計算後簡單拼接,沒有頭與頭之間的動態協調。每個 token 無論難易都走完全相同的計算路徑。這些設計當初都是為了讓模型能訓起來、能收斂的工程妥協。
深度學習過去十年的演進方向,如果抽象到最高層,就是一件事,把越來越多的結構性決策從人類設計者手中交還給模型自己。手工設計的卷積核被可學習的注意力替代了。固定的位置編碼被可學習的旋轉編碼替代了。固定的專家分配被可學習的路由替代了。現在,深度維度上的信息流動方式,也開始由注意力自己來決定了。
Karpathy 説我們還沒有把"Attention is All You Need"的字面意思當真。他可能説對了。但不是"注意力就夠了"這個意思,而是"注意力還沒有被用夠"。它在序列維度上已經進化了很多代,但在深度維度上才剛剛開始。
深度是注意力的下一個戰場。
本文來源:騰訊科技
