
Qwen3.5-Omni In-Depth Experience: This is What "AI Productivity" Should Look Like!
它讓音視頻不再是 “看完就過去” 的東西,而是可以檢索、複用、直接拿去幹活的 “數字資產”。
你一定有過這種經歷:開完一場兩小時的會議,錄像文件安安靜靜躺在網盤裏,但沒人願意回看——因為回看的成本幾乎等於再開一次會。
一條爆款帶貨視頻刷到了,你隱約覺得它的轉化邏輯值得學,但既沒時間逐幀拆解,拆了也不知道怎麼變成自己的腳本。
還有英文播客、發佈會直播、夾雜方言且需要覆盤的客服錄音——這些音視頻內容每天都在大量產生,但對絕大多數人來説,它們被"看過"或"聽過"之後,就再沒有然後了。
我們的日常中,大量非常非常有價值的音視頻內容無法被拆開、被檢索、更沒法總結經驗拿去複用。
而阿里千問剛剛發佈的 Qwen3.5-Omni,讓我們覺得這個問題開始有解了。
它是千問最新一代全模態大模型,採用混合注意力 MoE 架構,在海量文本、視覺及超過 1 億小時的音頻數據上做了原生多模態預訓練,在 215 項第三方性能測試中取得 SOTA,多項核心指標超越 Gemini-3.1 Pro。
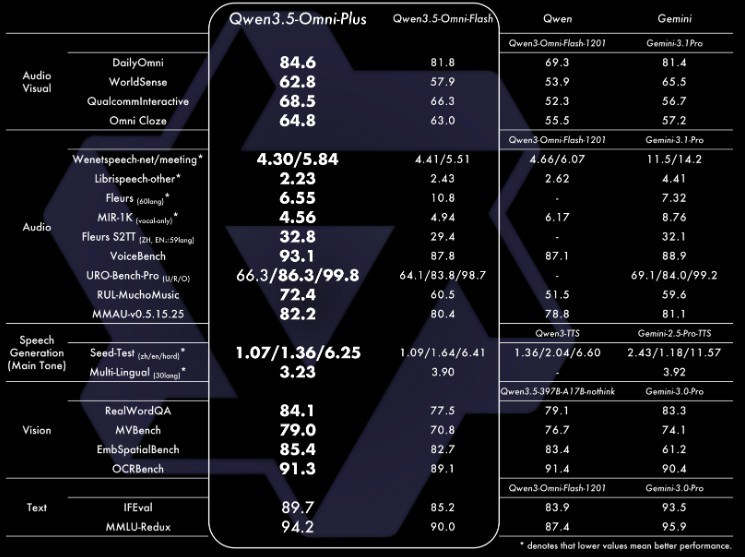
比跑分更值得説的,是我們在實測中實際體驗到的東西——經過幾輪極其刁鑽的極限測試後,這個全模態模型徹底震撼到我了:
- 我們讓它拆解了一支《沙丘》預告片——它不僅按時間戳做了結構化分析,還推理出了角色間的隱含關係,生成了帶節奏設計和調色建議的復刻分鏡腳本;
- 我們給了它一條爆款 TikTok 帶貨視頻——它拆出了完整的轉化歸因,輸出了可以直接遷移到其他行業的 5 步腳本模板;
- 我們對着一張畫得很醜的手繪草圖口述需求——它直接生成了能跑的 React 頁面,然後我們繼續口述修改,它一輪輪迭代下去,上下文始終沒丟。
這意味着,你可以把一場兩小時的會議錄像扔給它,拿回一份帶時間戳的結構化紀要和待辦清單;把一條競品的爆款視頻丟進去,直接拿到可遷移的腳本模板;用它給客服錄音做質檢,輸出情緒軌跡和話術評分。
它的意義,絕不僅僅是多模態能力的又一次參數升級。它讓我親眼看到,原本只能"看一遍就過去"的音視頻內容,是如何被生生拆解成可以直接拿去幹活的 “數據資產” 的。
而如果你給你的龍蝦接上 Qwen3.5-Omni,給你的龍蝦裝上 “眼睛” 和 “耳朵”,那麼你就能獲得一個真正能聽懂語音指令、看懂視頻內容、理解音頻信息,還會操作電腦的數字員工。
這,或許才是那場我們期待已久的、屬於全模態大模型的真正生產力革命。
接下來,我們先來看看實測細節,再聊聊這個模型正在改變什麼,以及阿里拿它在下一盤什麼棋。
拆電影、覆盤帶貨、口述寫代碼:全模態能力全面進化
(1)沙丘:不止是"看懂故事"
我們選了沒有字幕版的《沙丘》預告片作為第一個測試素材,來對 Qwen3.5-Omni 的多模態能力進行 “極限測試”。
預告片天生就是視頻理解領域最不友好的素材:密集的鏡頭切換、多線敍事、大量隱喻和視覺暗示,視聽密度極高。
而對於 Qwen3.5-Omni 來説,第一輪的結構化信息提取幾乎沒有難度:劇情時間線、關鍵鏡頭、畫面文字、説話人與台詞、角色陣營關係、情緒變化曲線,全部按時間戳精準剝離。
第二輪,我們指定了第 24 秒出現的台詞,要求它回答對應畫面、説話者和情緒。它準確定位到"She would need to be strong, like her mother",正確識別為保羅的畫外旁白而非現場對話,對應畫面為查妮沙漠逆光側臉特寫,情緒判斷——温柔、敬重、期許——與畫面完全吻合。

真正的考驗,在於第三輪的"深層推理追問"——
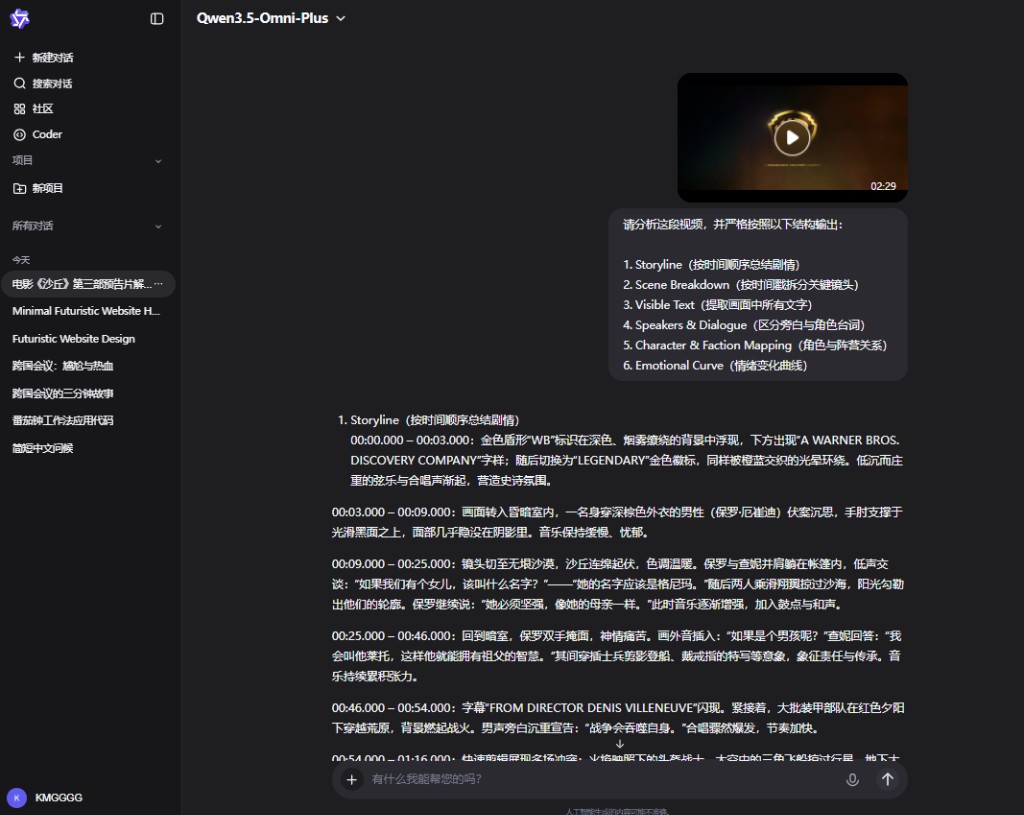
我們要求它分析角色間的"隱含關係"並給出鏡頭和台詞證據、識別預告片中的"伏筆"鏡頭及其對未來劇情的指向、生成一個 45 秒短視頻復刻分鏡腳本。
它準確識別出保羅與費德 - 羅薩之間的"鏡像宿敵"關係、保羅與傑西卡之間的"斷裂傳承"張力、查妮作為"人性錨點"的角色定位,而且附帶了視覺構圖證據和台詞對照。
它給出的復刻分鏡腳本也不是模糊的敍事概括,而是帶有"慢板抒情→快速剪輯→史詩爆發"的三段式節奏設計,甚至包含調色方向、音效提示和字幕處理建議。
説實話,到這一步,它已經不是在"看懂視頻",而是有點導演拆片的意思了。它把 LLM 的"視頻理解"能力,從摘要層推到了鏡頭語言解讀、關係推理層面。
(2)帶貨:從一條爆款 Tiktok 帶貨視頻裏,拆出轉化的底層邏輯
對更多人來説,更現實的問題是:它在真實世界,在日常工作中是不是真的 “有用”?
我們輸入了一條義烏招商類 TikTok 爆款帶貨視頻,要求 Qwen3.5-Omni 幫助我們拆解、復刻。
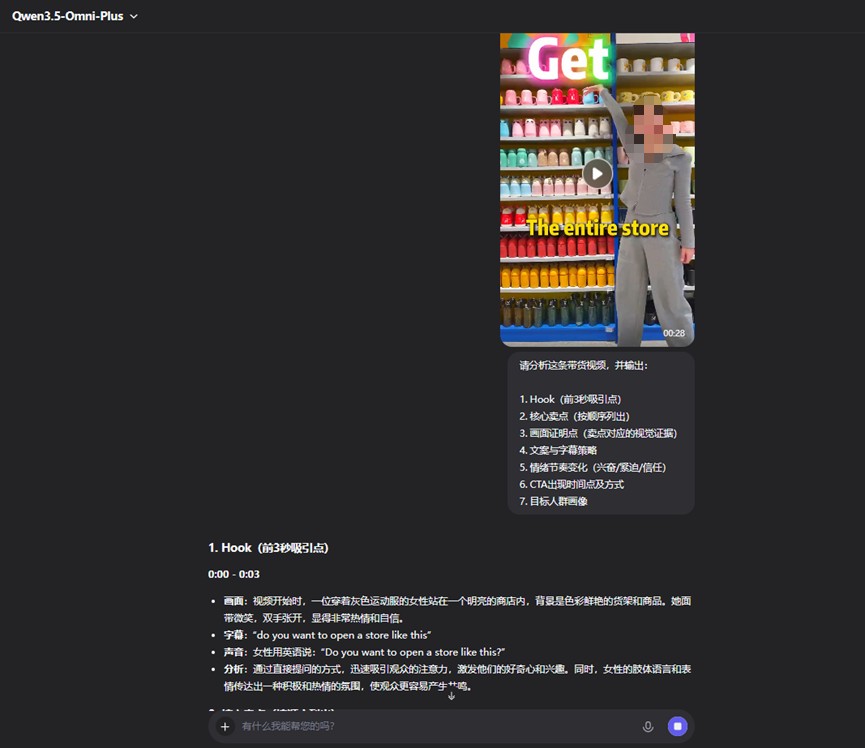
結果,模型不僅按 Hook、賣點排序、畫面證明點、字幕策略、情緒節奏、CTA 時間點、目標人羣七個維度完成了結構化拆解,它的歸因分析也極具洞察力:三級物理證據鏈構建"所見即所得的信任"、"2 萬種 SKU + 20 美分均價"製造數字錨點、保姆式全案承諾實現風險逆轉。
換句話説,它看出來了:這條視頻賣的不是商品,而是確定性。
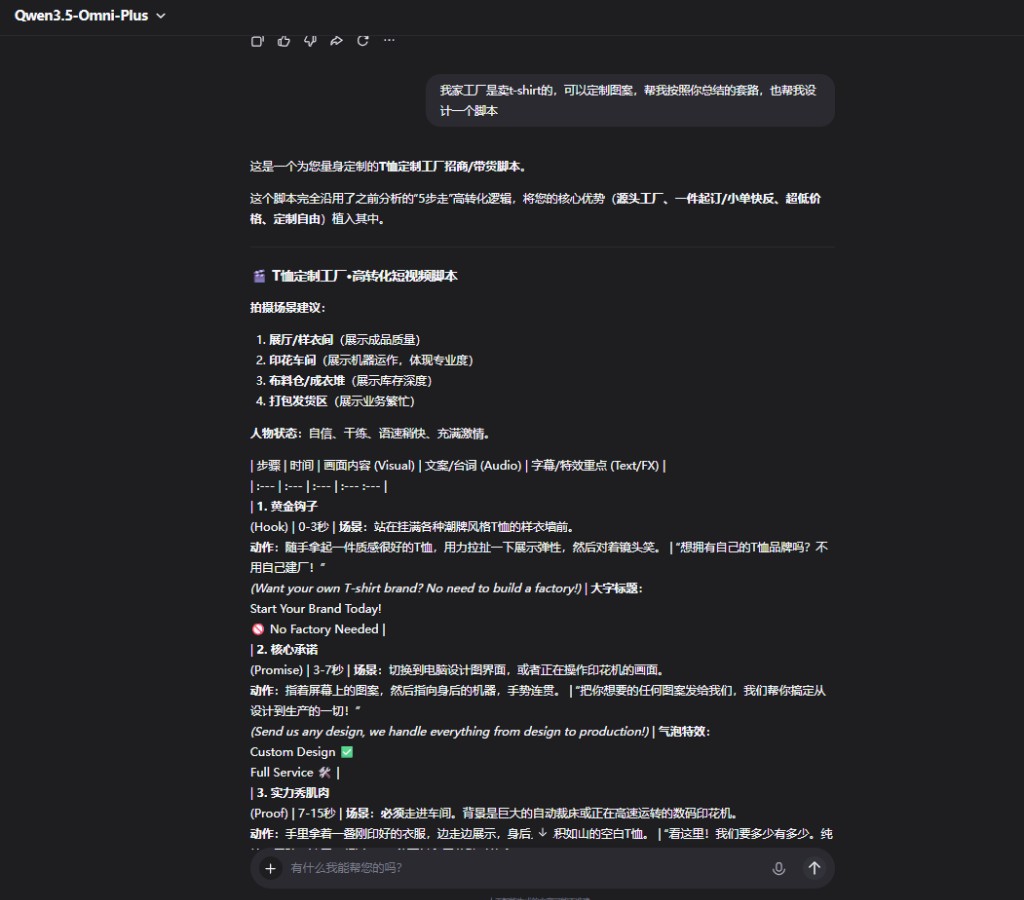
為了驗證它是不是在生搬硬套營銷學名詞,我們告訴它,"我家工廠是賣 T 恤的,幫我按這個套路設計一個腳本",要求它把這套邏輯遷移到"T 恤定製工廠"場景。
結果,它不僅把剛剛分析出的 5 步轉化模板成功遷移到 T 恤場景,還把 Hook 極其自然地改成了"拉扯 T 恤展示彈性",把實力證明換成了"印花機噴墨特寫 + 揉搓不掉色",甚至附帶了評論區運營引導私信的實操建議。
也就是説,大模型不再只是內容理解工具,它已經可以充當不知疲倦的電商分析師和社交媒體運營專家。
(3)口述一個 App:邊看、邊説、邊改
第三個測試,堪稱 “Vibe Coding” 的升級版——"音視頻 Vibe Coding"。
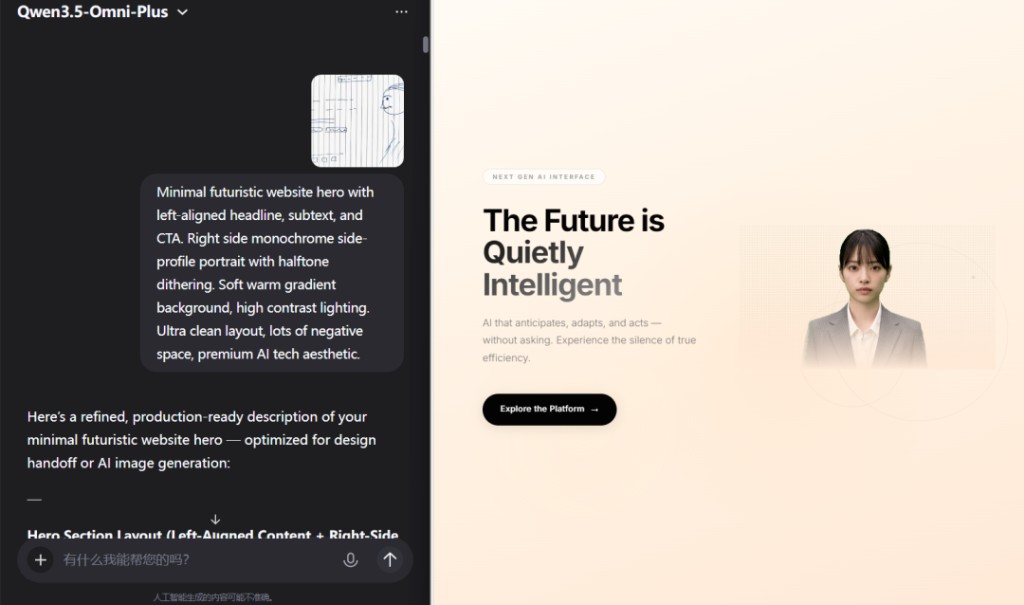
我們手繪了一張故意畫得很粗糙的 APP 線框圖,打開攝像頭,手持草圖對着鏡頭口述:"你看這個是我畫的界面草圖……請用 React 幫我生成完整代碼,可以直接運行的。"
它識別了手繪佈局並生成了 React 代碼。接着我們繼續口述修改——"導航欄改成側邊欄,主按鈕放大一倍換圓角",同時上傳替換圖片。之後又測了深色主題、進度條動畫、按壓反饋等迭代,它始終能延續上下文,不丟失之前的修改。
幾輪修改後,網頁成功上線。
整體體驗上來説,它接住了人類最真實的交互方式:邊看、邊説、邊改。不是以前那種"AI 生成代碼你自己去調"的體驗,更像一個經驗豐富的開發者坐在你的旁邊。
(4)連起來看
從《沙丘》的複雜敍事,到帶貨的商業分析,再到口述做 App 的隨性交互,如果我們把上面的幾個測試案例串起來看就會發現:
Qwen3.5-Omni 成功證明了:它能把複雜的、混亂的、連續的輸入,變成可以直接拿去用的結果。
另外補充兩個我們也測了但沒展開寫的用例:遊戲視頻生成解説:網頁端出文案,API 端出 TTS 語音;"24 小時 AI 新聞編輯部"——50 分鐘國際新聞發佈會音頻走完信息提取、雙語稿件生成和語音播報,效果都不錯,感興趣的朋友也可以試試。
底層改變:從"看懂內容"到"拆成資產"
前面三個場景能跑通,不僅因為"能力變強了",而是底層產品設計發生了質變:它把連續、混雜、難以檢索的音視頻流,強制拆解為高度結構化的中間層。
(1)拆得多細:不是摘要,是字段級的結構化資產
翻開官方 API 文檔你會發現,Qwen3.5-Omni 對音視頻的推薦輸出格式不是一句籠統的摘要,而是三層硬結構:
- Storyline(按時間戳融合音畫細節的故事線);
- Visible Text(帶起止時間和外觀特徵的畫面文字清單);
- Speakers and Transcript(含説話人身份、口音、語氣、情緒的逐字稿)。
換句話説,它拿到的不再是"一團視頻",而是一份可以被代碼直接調用、檢索和執行的結構化資產。這就是沙丘測試能做到精確回溯,TikTok 測試能輸出可遷移模板的底層原因。
支撐這種顆粒度的,是實打實的模型基礎能力——混合注意力 MoE 架構,超過 1 億小時音頻數據的原生多模態預訓練,模型智力與 qwen3.5-plus 同一水平,215 項第三方測試取得 SOTA。
(2)拆得多長:超大上下文窗口
256K 上下文窗口,支持超過 10 小時音頻、超過 400 秒 720P 視頻。
長內容真正的難點從來不是"看完",而是跨段關聯和證據回溯——扔進 10 小時的會議錄音,問"第 5 分鐘提到的人在第 30 分鐘説了什麼";輸入帶貨直播錄屏,讓它揪出誇大宣傳的時間點並附上畫面和台詞證據;用它給客服錄音做質檢,輸出情緒軌跡和話術評分。
這些過去高度依賴人力、極易出錯的信息整理工作,Qwen3.5-Omni 正在試圖接管。
(3)交互:是動態接口
實時交互這一面,它支持智能語義打斷——不會因為你咳嗽一聲或隨口説個"嗯"就中斷髮言,過濾掉了無意義的背景音干擾。
它原生支持聯網搜索的 FunctionCall,能自主判斷是否需要拉起搜索來回應實時問題,開發者還能在回執中看到精確的計量信息。這從工程層面緩解了企業用大模型時最頭疼的"時效性與幻覺"問題。
語音表達層的能力提升同樣很有價值,現在,它支持 113 種語種和方言的語音識別,三十六種語言和方言的語音合成,內置 47 個多語言説話人和 8 個方言説話人。
在我們的實測中,無論是自稱"聲音像温熱奶茶"的客服角色 Tina,還是四川話的"晴兒",角色感和產品感都很強。
這不只是"聽得懂更多",而是為海外客服、審核質檢、有聲讀物、播客配音這些高頻場景備足了彈藥。
一句話簡單總結,Qwen3.5-Omni,讓音視頻變得"可拆"——不是"看懂了",而是拆成可以檢索、可以複用、可以直接拿去幹活的現成素材。
阿里真正想賣的,也不只是一個模型
聊完產品和技術,值得把視線從模型本身移開,看看阿里最近在組織和產品上的一系列動作——一條清晰的商業暗線就會浮出來。
不久前,阿里成立了由 CEO 吳泳銘直管的 Alibaba Token Hub(ATH)事業羣,明確提出以 “創造 Token、輸送 Token、應用 Token” 為核心。其中,首次亮相的 “悟空事業部” 定位極為明確:“B 端 AI 原生工作平台,將模型能力深度融入企業工作流”。
而在釘釘最新發布的 “悟空” 產品中,核心邏輯已經從 “溝通即生成” 進化為了 “溝通即執行”(CLI 化,AI 直接調底層接口)。AI 不再只是陪你聊天,而是被要求自己去網上看競品視頻、分析小紅書爆款、跨系統拉取數據、甚至生成數據動畫。
注意這裏的關鍵詞:看視頻、聽音頻、跨平台執行。當 AI Agent 開始長出"手腳",自主去處理大量音視頻內容時,它對全模態理解能力的需求和 Token 的消耗量,都將遠超純文本對話時代。
在這個背景下回看 Qwen3.5-Omni,它的極低定價(每百萬 Tokens 輸入不到 0.8 元,比 Gemini-3.1 Pro 的 1/10 還低)和強大的結構化音視頻能力,更像是在為以悟空為代表的阿里 B 端企業級 Agent 大規模落地,儲備高性價比、穩定的全模態基礎設施。
要知道,把長達數小時的音視頻拆解成精細的結構化數據,過去意味着企業需要拼裝一整條鏈路——ASR 轉寫、文本大模型、視覺理解模型、TTS 合成——成本高、鏈路長、斷點多。
而現在,一個端到端的全模態模型,把這件事的門檻徹底踏平了。
我覺得 Qwen3.5-Omni 真正值得被記住的,不是它今天能看懂一段多複雜的電影預告片而是從這一刻起,它開始能把音視頻內容,變成企業工作流裏可以切實處理、複用的 “數字資產”——
全模態大模型驅動的生產力革命,正在來臨。
