
周鴻禕談大模型扎堆:現在説超越 ChatGPT 的叫吹牛

一天前科大訊飛發佈訊飛星火認知大模型,稱已經在文本生成、知識問答、數學能力三大能力上超過 ChatGPT。
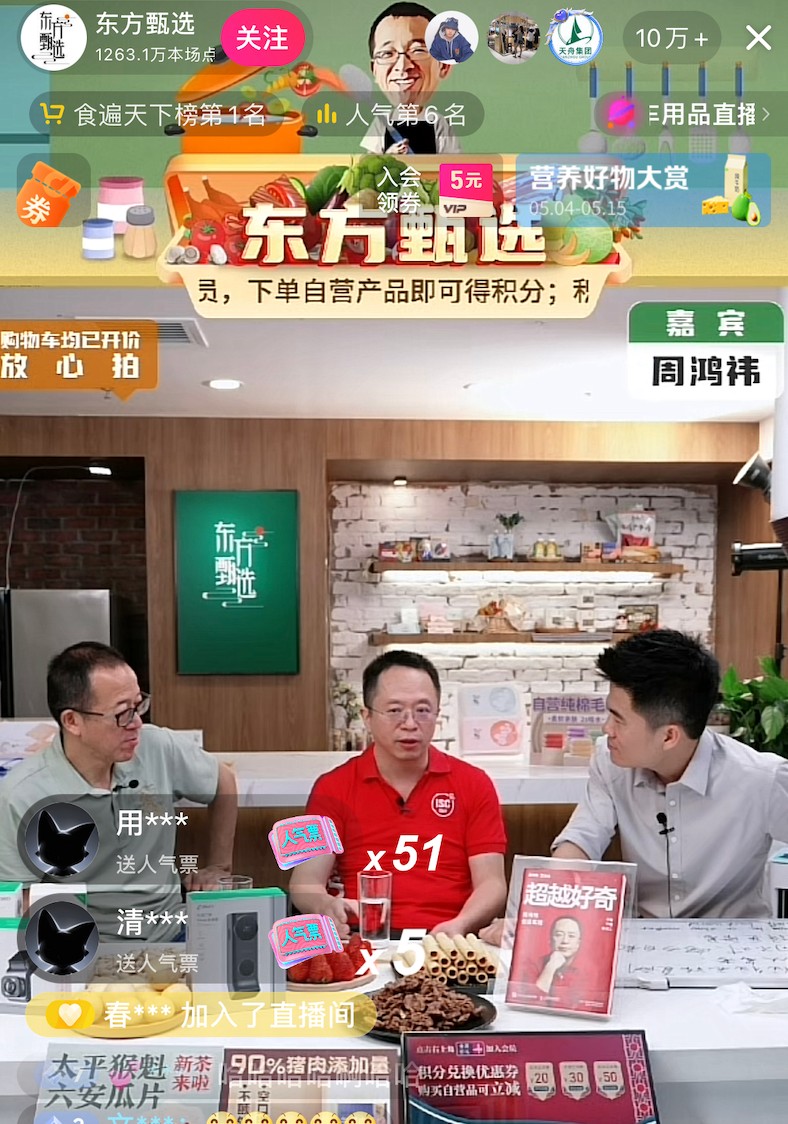
跨入東方甄選直播間的第一件事,三六零 (601360.SH,簡稱 “360”) 集團創始人周鴻禕先嚐了嘗桌上擺放了零食。
5 月 7 日,周鴻禕連軸轉場俞敏洪與東方甄選直播間,銷售其名下兩本書——《超越好奇》《數字安全網絡戰》。在東方甄選直播間不足十分鐘的時間內,《超越好奇》的銷量已超過在俞敏洪直播間一個半小時的銷售量。
周鴻禕在東方甄選直播間內順應了董宇輝的主播風格,主要以閒聊為主,淺談了何為創業、年輕人的好奇心等。在俞敏洪直播間內,周鴻禕談及對當下火熱大模型與 ChatGPT 的看法,他稱,以前的人工智能技術很碎片,“不通用” 的問題導致大家對它喪失了熱情。
OpenAI 的成功讓行業熱議是否過去中國公司過於 “功利” 地追求盈利,而不願長期投入技術。對此,周鴻禕認為,這是因為公司都比較現實,美國公司也一樣,Meta(NASDAQ:META) 搞元宇宙虧了 100 億美元也受不了,OpenAI 最牛的一點就是堅信通用人工智能能成功,且最終把這條路給趟出來了,這裏面既有運氣也有堅持。
至於目前國內多家公司密集推出大模型產品的現象,周鴻禕稱,首先要感謝 OpenAI 與 ChatGPT 把方向跟技術路線探索出來了,第二要感謝開源生態與開放論文,剩下留給公司們要做的主要是工程化的訓練層面,這是當下大家都能做大模型的原因。
至於目前國內大模型發展與OpenAI之間的差距,周鴻禕稱他同意王小川的觀點——差距最少有兩年。此前王小川認為OpenAI比國內領先三年時間。追上GPT-3.5可能一年時間是有機會的,但目前OpenAI已經達到GPT-4的級別,GPT-5也在訓練過程當中了,因此“追上”需要三年。
回到國內大模型發展問題,周鴻禕表示,互聯網公司都去做大模型的原因,是因為沒人能篤定某一家公司能做出來成功的大模型產品。但這個技術對中國很重要,它是工業級的,對各行各業都能帶來工業革命級的推動。但在早期,周鴻禕認為後來者在大模型技術領域肯定是模仿與 “抄襲”,但在做的過程中一定會越來越瞭解,未來有可能會彎道超車、後來者居上,“但上來就説能超越,那才叫吹牛呢”,周鴻禕表示。
5 月 6 日,科大訊飛 (002230.SZ) 推出星火認知大模型,科大訊飛董事長劉慶峯表示,認知大模型成為通用人工智能的曙光,科大訊飛有信心實現 “智能湧現”。當前訊飛星火認知大模型已經在文本生成、知識問答、數學能力三大能力上超過 ChatGPT。
“到今年的 10 月 24 日(科大訊飛全球開發者節),我們希望星火能夠在通用認知大模型能力上對標 ChatGPT,在中文上超越 ChatGPT,在英文上達到跟它相當的水平。” 劉慶峯表示。
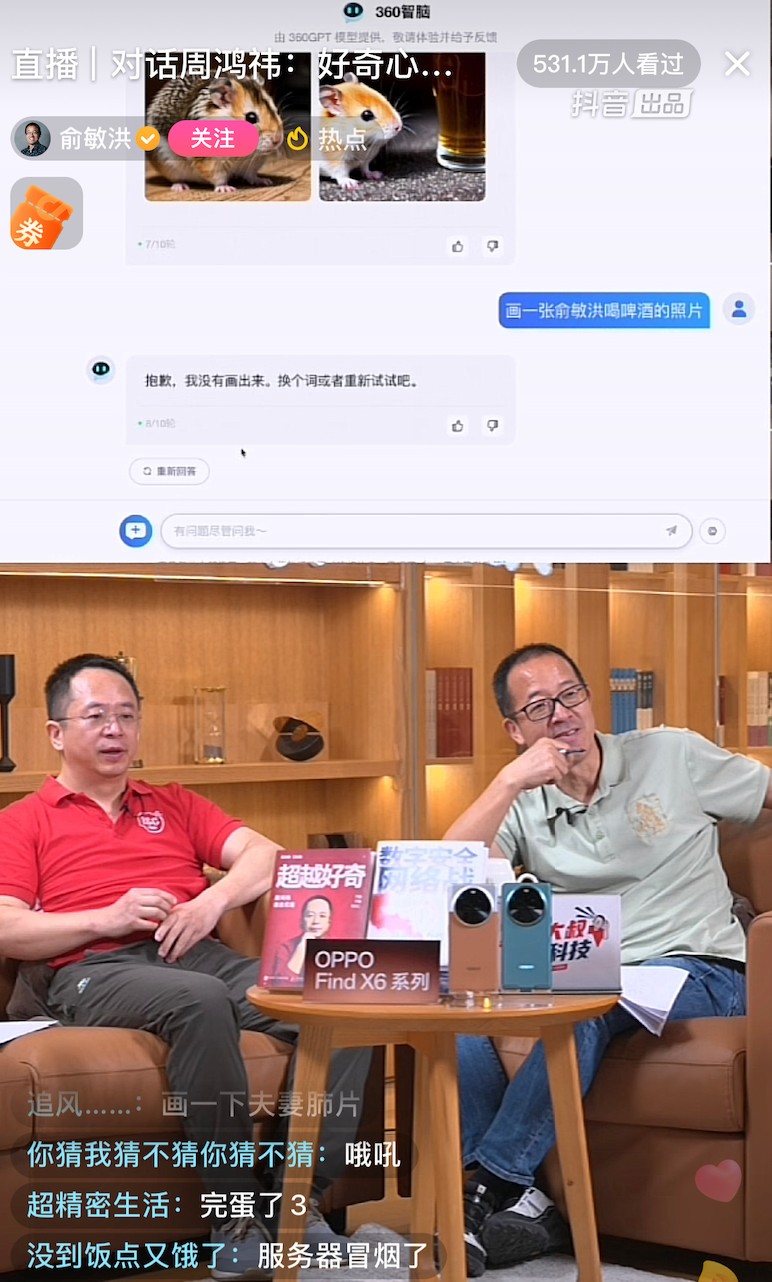
此前 360 推出大模型產品 “360 智腦”,在俞敏洪直播間,周鴻禕也對 “360 智腦” 進行了多模態演示。在製圖環節,“360 智腦” 完成了周鴻禕與俞敏洪合照、松鼠喝啤酒等要求,但在製作 “俞敏洪喝啤酒” 圖片環節發生卡頓,據瞭解是因 “360 智腦” 儲備俞敏洪圖片不足所致。
5 月 5 日收盤,360 股價 15.45 元,漲 2.73%,總市值 1104 億元。
文章作者
- 呂倩
