
AI 引爆,HBM 崛起

英偉達用 A100 和 H100 兩塊顯卡,輕鬆拿下了萬億美元的市值,坐穩了 AI 時代的寶座,而它們用的顯存,正是 AMD 當初力推的 HBM。
近年來,因為 AI 芯片的火熱,HBM 作為當中一個核心組件,在近年來的關注熱度水漲船高。關於 HBM 技術的細節,可以參考半導體行業觀察之前的文章《存儲巨頭競逐 HBM》。在本文中,我們將回顧 HBM 的崛起故事,幫助大家瞭解這個高帶寬內存的前世今生。
以下為文章正文:
2015 年 6 月 17 日,AMD 中國在北京望京召開發佈會。
這場發佈會上,媒體的目光全集中在某款重磅產品之上,它就是全新的 Radeon R9 Fury X 顯卡,其採用代號為 Fiji XT(斐濟羣島)的 28nm 製程 GPU 核心,採用 4GB HBM 堆疊顯存,擁有 64 個計算單元(CU)、4096 個 GCN 架構流處理器(SP),核心頻率為 1050MHz,單精度浮點性能達到了 8.6TFlops,而 HBM 顯存擁有 4096 bit 帶寬,等效頻率 1Ghz,顯存總帶寬達到了 512GB/S,除了顯存容量外,各項配置無愧於旗艦之名。

雖説這是 HBM 顯存首次亮相,但 AMD 早已聯合 SK 海力士等廠商潛心研發多年,而 Fury X 作為首款搭載 HBM 的顯卡,自然會被 AMD 寄予厚望。
時任 AMD CEO 的蘇姿豐表示,HBM 採用堆疊式設計實現存儲速度的提升,大幅改變了 GPU 邏輯結構設計,DRAM 顆粒由 “平房設計” 改為 “樓房設計”,所以 HBM 顯存能夠帶來遠遠超過當前 GDDR5 所能夠提供的帶寬上限,其將率先應用於高端 PC 市場,和英偉達(NVIDIA)展開新一輪的競爭。
針對 R9 Fury X 僅有 4GB 顯存,而 R9 290X 新版本卻配備了 8GB GDDR5 顯存這一問題,AMD 事業羣 CTO Joe Macri 還特意回應表示,顯存容量其實並不是問題,GDDR5 可以做到很大,但也有着很嚴重的浪費,其實有很多空間都未得到充分利用,AMD 未來會深入研究如何更高效率地利用這 4GB HBM 顯存。
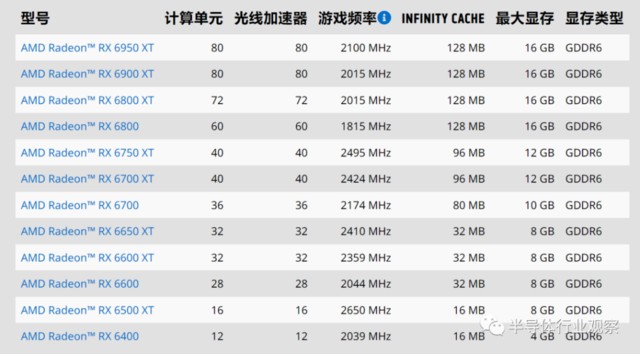
八年多時間過去了,AMD 官網上掛着的 RX 7000 系列全部採用 GDDR6 顯存,當初辛辛苦苦和海力士合作多年才得來的 HBM 顯存早已不見蹤影,只有用於 AI 計算的加速卡還殘留着當初的豪言壯語。
而曾經的對手英偉達,用 A100 和 H100 兩塊顯卡,輕鬆拿下了萬億美元的市值,坐穩了 AI 時代的寶座,而它們用的顯存,正是 AMD 當初力推的 HBM。
苦研七年作嫁衣
時間再倒回 2015 年,AMD 事業羣 CTO Joe Macri 在紐約分析師大會上,接受了媒體的專訪,針對首次落地應用的 HBM 做了一系列回答。
Macri 表示,AMD 自 2009 年開始,就已經着手 HBM 的研發工作,在長達 7 年的時間裏,AMD 與 SK 海力士在內的眾多業界夥伴一起完成了 HBM 的最終落地。
他首先談到了 HBM 顯存的必要性,2015 年主流的顯存規格是 GDDR5,經過多年的使用和發展已經進入了瓶頸期,迫切需要新的替代技術,簡單來講,就是 GPU 的功耗不可能無限制地增長下去,越來越大的高規格顯存正在擠壓 GPU 核心的功耗空間,以前一張卡就 200W 功耗,顯存分到 30W,而之後的大容量顯存卻水漲船高,60W、70W、80W……再加上核心的提升,一張顯卡往往有五六百瓦的功耗,也難怪被稱之為核彈卡。

Macri 覺得,顯存面臨的關鍵問題就是顯存帶寬,它卻決於顯存的位寬和頻率,位寬都是 GPU 決定的,太高了會嚴重增大 GPU 芯片面積和功耗,所以高端顯卡一直停留在 384/512 位。同時,GDDR5 的頻率已經超過 7GHz,提升空間不大了。另外,GDDR5(包括以前的顯存) 都面臨着 “佔地面積” 的問題。一大堆顯存顆粒圍繞在 GPU 芯片周圍,這已經是固定模式,GDDR5 再怎麼縮小也無法改變,而且已經不可能再繼續大幅度縮小了。
即使在今天來看,AMD 這番關於顯卡功耗的話也挑不出什麼毛病,GDDR5 的頻率確實到了上限,而功耗問題也一直困擾着廠商和消費者,英偉達最新的 RTX 40 系顯卡為了縮減功耗和成本,就對顯存位寬開了刀,功耗倒是小了,但是跑高分辨率遊戲又變得不利索了。
事實上,行業內大部分人都覺得 GDDR 已經不行了到頭了,但還是捏着鼻子繼續用,因為大家的共識是,成熟且落後的技術總比先進但不可靠的技術好,只有 AMD 徹底改變了思路,畢竟這家公司從誕生起,就不缺乏改變的勇氣。
勇氣是有了,不過 AMD 能夠在顯存上革新,還是極大程度上受到了大洋彼岸日本的啓發。
1999 年,日本超尖端電子技術開發機構(ASET)開始資助採用 TSV 技術開發的 3D IC 芯片,該項目名為 “高密度電子系統集成技術研發”;2004 年,爾必達開始研發 TSV 技術,同時接受了來自日本政府的新能源與產業技術開發組織 (NEDO) 的資助;2006 年,爾必達與 NEC、OKI 共同開發出採用 TSV 技術的堆棧 8 顆 128Mb 的 DRAM 架構……
什麼是 TSV 呢?TSV 全稱為 Through Silicon Via,是一種新型三維堆疊封裝技術,主要是將多顆芯片 (或者晶圓) 垂直堆疊在一起,然後在內部打孔、導通並填充金屬,實現多層芯片之間的電連接。相比於傳統的引線連接多芯片封裝方式,TSV 能夠大大減少半導體設計中的引線使用量,降低工藝複雜度,從而提升速度、降低功耗、縮小體積。
這項技術不光能運用於 DRAM 領域,在 NAND 和 CIS 上也有廣闊的前景,其最早就是在閃存上得以實踐:東芝在 2007 年 4 月推出了具有 8 個堆疊芯片的 NAND 閃存芯片,隨後海力士又在 2007 年 9 月推出了具有 24 個堆疊芯片的 NAND 閃存芯片。

2009 年,爾必達宣佈已成功開發業內第一款 TSV DRAM 芯片,其使用 8 顆 1GB DDR3 SDRAM 堆疊封裝而來,並在 2011 年 6 月開始交付樣品,TSV 技術正式走上內存這個大舞台。
緊隨其後的是韓國與美國廠商,2011 年 3 月,SK 海力士宣佈採用 TSV 技術的 16GB DDR3 內存(40nm 級)研發成功, 9 月,三星電子推出基於 TSV 技術的 3D 堆疊 32GB DDR3(30nm 級),10 月,三星電子和美光科技聯合宣佈推出基於 TSV 技術的混合內存立方 (HMC) 技術。
AMD 在收購 ATI 後,就已經打起了顯存的主意,但想要從頭研發全新的顯存標準,光靠自己的 GPU 部門閉門造車顯然是不夠的,於是 AMD 拉來了幾個至關重要的合作伙伴:有 3D 堆疊內存經驗的韓廠海力士,做硅中介層的聯電,以及負責封裝測試的日月光和 Amkor。
HBM 應運而生,前面提到了 GDDR 陷入到了內存帶寬和功耗控制的瓶頸,而 HBM 的思路,就是用 TSV 技術打造立體堆棧式的顯存顆粒,讓 “平房” 進化為 “樓房”,同時通過硅中介層,讓顯存連接至 GPU 核心,並封裝在一起,完成顯存位寬和傳輸速度的提升,可謂是一舉兩得。
2013 年,經過多年研發後,AMD 和 SK 海力士終於推出了 HBM 這項全新技術,還被定為了 JESD235 行業標準,HBM1 的工作頻率約為 1600 Mbps,漏極電源電壓為 1.2V,芯片密度為 2Gb(4-hi),其帶寬為 4096bit,遠超 GDDR5 的 512bit。

除了帶寬外,HBM 對 DRAM 能耗的影響同樣重要,同時期的 R9 290X 在 DRAM 上花費了其 250W 額定功耗的 15-20%,即大約 38-50W 的功耗,算下來 GDDR5 每瓦功耗的帶寬為 10.66GB/秒,而 HBM 每瓦帶寬超過 35GB/秒,每瓦能效提高了 3 倍。
此外,由於 GPU 核心和顯存封裝在了一起,還能一定程度上減輕散熱的壓力,原本是一大片的散熱區域,濃縮至一小塊,散熱僅需針對這部分區域,原本動輒三風扇的設計,可以精簡為雙風扇甚至是單風扇,變相縮小了顯卡的體積。
反正好處多得數不清楚,不論是 AMD 和 SK 海力士,還是媒體和眾多玩家,都認定了這才是未來的顯存,英偉達主導的 GDDR 已經過時了,要被掃進歷史的垃圾堆了。
壞處嘛,前文中提到的旗艦顯卡僅支持 4GB 顯存算一個,畢竟高帶寬是用來跑高分辨率的,結果顯存大小縮水直接讓 HBM 失去了實際應用意義。
而價格更是壓倒 AMD 的最後一根稻草:HBM1 的成本已不可考,但 8GB HBM2 的成本約 150 美元,硅中介層成本約 25 美元,總計 175 美元,同時期的 8GB GDDR5 僅需 52 美元,在沒有考慮封測的情況下,HBM 成本已經是 GDDR 的三倍左右,一張 RX Vega 56 零售價才 400 美元,一半的成本都花在了顯存之上,GPU 部門本來是要補貼 CPU 部門的,結果現在情況卻要反過來,誰又能擔待得起呢?

因而 AMD 火速取消了後續顯卡的 HBM 顯存搭載計劃,老老實實跟着英偉達的步伐走了,在 RX 5000 系列上直接改用了 GDDR6 顯存,HBM 在 AMD 的遊戲顯卡上二世而亡。
反觀英偉達,卻是以逸待勞,2016 年 4 月,英偉達發佈了 Tesla P100 顯卡,內置 16GB HBM2 顯存,帶寬可達 720GB/s,具備 21 Teraflops 的峯值人工智能運算性能。
英偉達在 HBM 上並未像 AMD 一樣深耕多年,怎麼突然反手就是一張搭載了 HBM2 的顯卡,對 AMD 發起了反攻的號角呢?
背後的原因其實還頗有些複雜,Tesla P100 顯卡所用的 HBM2 顯存,並非來自於 AMD 的合作伙伴 SK 海力士,而是隔壁的三星電子,同樣是韓廠的它,在基於 TSV 技術的 3D 堆疊內存方面的開發並不遜色於海力士多少,在奮起直追的情況下,很快就縮小了差距,而英偉達正有開發 HBM 相關顯卡之意,二者一拍即合。
至於 AMD 與聯電、日月光、Amkor 等好不容易搞定的硅中介層與 2.5D 封測,英偉達則是找到了業界的另一個大佬——台積電,看上了它旗下的先進封裝技術 CoWoS(Chip-on-Wafer-on-Substrate),其早在 2011 年就推出了這項技術,並在 2012 年首先應用於 Xilinx 的 FPGA 上,二者同樣是一拍即合。
此後的故事無需贅言,英偉達從 P100 到 V100,從 A100 再到 H100,連續數張高算力的顯卡幾乎成為了 AI 訓練中的必備利器,出貨量節節攀升,甚至超越了傳統的遊戲顯卡業務,而 HBM 也在其中大放光彩,成為了鑲嵌着的最耀眼的一顆寶石。
起了個大早,趕了個晚集,是對 AMD 在 HBM 上的最好概括,既沒有憑藉 HBM 在遊戲顯卡市場中反殺英偉達,反而被英偉達利用 HBM 鞏固了 AI 計算領域的地位,白白被別人摘了熟透甜美的桃子。
三家分內存
在 AMD 和英偉達這兩家 GPU 廠商爭鋒相對之際,三家領先的內存廠商也沒閒着,開始了在 HBM 市場的你追我趕的歷程。
2013 年,SK 海力士宣佈成功研發 HBM1,定義了這一顯存標準,但它和 AMD 一樣,好不容易得來的優勢卻沒保持得太久。
2016 年 1 月,三星宣佈開始量產 4GB HBM2 DRAM,並在同一年內生產 8GB HBM2 DRAM,後來者居上,完成了對本國同行的趕超,與 HBM1 相比,顯存帶寬實現了翻倍。
2017 年下半年,SK 海力士的 HBM2 姍姍來遲,終於宣佈量產;2018 年 1 月,三星宣佈開始量產第二代 8GB HBM2“Aquabolt”。
2018 年末,JEDEC 推出 HBM2E 規範,以支持增加的帶寬和容量。當傳輸速率上升到每管腳 3.6Gbps 時,HBM2E 可以實現每堆棧 461GB/s 的內存帶寬。此外,HBM2E 支持最多 12 個 DRAM 的堆棧,內存容量高達每堆棧 24GB。與 HBM2 相比,HBM2E 具有技術更先進、應用範圍更廣泛、速度更快、容量更大等特點。

2019 年 8 月,SK 海力士宣佈成功研發出新一代 “HBM2E”;2020 年 2 月,三星也正式宣佈推出其 16GB HBM2E 產品 “Flashbolt”,於 2020 年上半年開始量產。
2022 年 1 月,JEDEC 組織正式發佈了新一代高帶寬內存 HBM3 的標準規範,繼續在存儲密度、帶寬、通道、可靠性、能效等各個層面進行擴充升級,其傳輸數據率在 HBM2 基礎上再次翻番,每個引腳的傳輸率為 6.4Gbps,配合 1024-bit 位寬,單顆最高帶寬可達 819GB/s。
而 SK 海力士早在 2021 年 10 月就發佈了全球首款 HBM3,並於 2022 年 6 月正式量產,供貨英偉達,擊敗了三星,再度於 HBM 上拿到了技術和市場優勢。
三星自然也不甘示弱,在它發佈的路線圖中,2022 年 HBM3 技術已經量產,2023 年下半年開始大規模生產,預計 2024 年實現接口速度高達 7.2Gbps 的下一代 HBM 技術——HBM3p,將數據傳輸率進一步提升 10%,從而將堆疊的總帶寬提升到 5TB/s 以上。
講到這裏,大家不免會心生疑問,都説了是三家分內存,這三星和海力士加一塊就兩家啊,還都是韓國的,另外一家跑哪去了呢?
身在美國的美光當然沒有忽視顯存市場,作為爾必達的收購者,它對於 3D 堆疊的 TSV 技術怎麼也不會陌生,甚至在 HBM 發佈之前,還有不少 TSV 技術方面的優勢。
但是美光卻沒跟着 AMD 或英偉達去鼓搗 HBM 技術,而是回頭選擇了英特爾,搞出了 HMC(混合內存)技術,雖然也使用了 TSV,但它有自己的控制器芯片,並且完全封裝在 PCB 基板之上,和 HBM 截然不同,也完全不兼容。
2011 年 9 月,美光正式宣佈了第一代 HMC,並在 2013 年 9 月量產了第二代 HMC,但響應者卻寥寥無幾,第一個採用 HMC 內存的處理器是富士通的 SPARC64 XIfx,其搭載於 2015 年推出的富士通 PRIMEHPC FX100 超算,而後就鮮見於各類產品中。
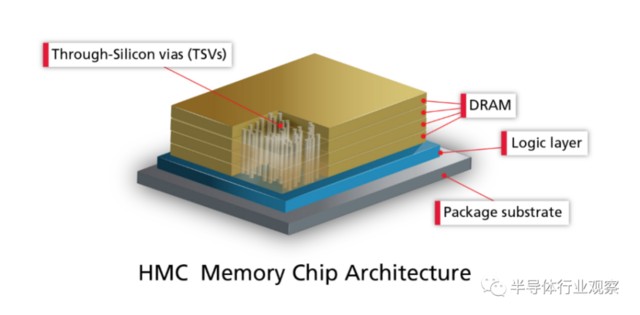
隨着 2018 年 8 月,美光宣佈正式放棄 HMC 後,才匆匆忙忙轉向 GDDR6 和 HBM 產品的研發,幸好 3D 堆疊技術的底子還在那裏,不至於説完全落後於兩個韓廠。2020 年,美光正式表示將開始提供 HBM2 產品,用於高性能顯卡,服務器處理器等產品,其在財報中預計,將在 2024 年第一季度量產 HBM3 產品,最終趕上目前領先的競爭對手。
AI 大潮仍然席捲全球,而英偉達 H100 和 A100 顯卡依舊火熱,HBM 作為內存市場的新蛋糕,卻是最鮮美的一塊。芯片行業諮詢公司 SemiAnalysis 表示,HBM 的價格大約是標準 DRAM 芯片的五倍,為製造商帶來了更大的總利潤。目前,HBM 佔全球內存收入的比例不到 5%,但 SemiAnalysis 項目預計到 2026 年將佔到總收入的 20% 以上。
這塊鮮美的蛋糕大部分留給了先行者,集邦諮詢調查顯示,2022 年三大原廠 HBM 市佔率分別為 SK 海力士 50%、三星約 40%、美光約 10%,十成裏面佔一成,美光自認為產品不遜於韓廠,但市場卻從不會為某個自恃技術領先的廠商網開一面。
總結
當初爾必達的坂本幸雄認為日本半導體輸人不輸陣,時任美光 CEO 莫羅特亞在接受採訪時也表示,AI 領域不光有 HBM,還包含高密度 DDR5、美光定製 LP DRAM 以及一部分圖形內存,概括來説,就是輸了 HBM 但還沒在 AI 上認輸。
倘若讓這倆 CEO 總結失敗的教訓,恐怕只能發出一句 “時也,命也,運也,非吾之所能也” 之淚的感慨吧,輸當然是不可能輸的,美光和爾必達即使倒閉也不會説技術不行,把過錯歸咎於市場,落了個一身輕鬆。
再回過頭來看,AMD 在 2015 年發佈 R9 Fury X 時的判斷錯了嗎?當然沒錯,內存帶寬的的確確到了瓶頸,從 GDDR5 到 GDDR6X 幾乎沒有進步,但在遊戲顯卡,可以採用大型緩存作為幀緩衝區,讓成本較低的 GDDR 接着上路,但數據中心和 AI 加速卡的帶寬問題卻非 HBM 不可,成本在這一領域反倒成了最不起眼的問題。
如今 AMD 調轉船頭,再戰 AI 領域,希望 HBM 能讓他們在這個市場騰飛。
