
AI「未來指南」!OpenAI 安全團隊負責人:AI Agent「詳細教程」

所謂 AI Agent,其實就是 LLM(大語言模型)Agent,每次迭代時,它們都會生成自我導向的指令和操作,可以理解成一個能夠自動執行任務的「機器人」。由於它可以連接到各種數據源,並通過 API 與環境進行交互,所以這個「機器人」又存在着很多類型,每個類型都有特殊的技能,比如搜索網頁、與文檔庫交互,乃至通過自問自答的方式解決問題。
近期,AI Agent 再度在圈內爆火。
所謂 AI Agent,其實就是 LLM(大語言模型)Agent,每次迭代時,它們都會生成自我導向的指令和操作,可以理解成一個能夠自動執行任務的「機器人」。
由於它可以連接到各種數據源,並通過 API 與環境進行交互,所以這個「機器人」又存在着很多類型,每個類型都有特殊的技能,比如搜索網頁、與文檔庫交互,乃至通過自問自答的方式解決問題。
那麼,建立這樣一個 AI Agent 到底包含了哪些內容,可以提供什麼樣的能力?
6 月底,OpenAI 的 Safety 團隊的負責人 Lilian Weng 發佈了一篇 6000 字的博客,詳細介紹了 AI Agent,並認為,這將使 LLM 轉為通用問題解決方案的途徑之一。
本文將根據這篇博客總結一下關於 AI Agent 的相關內容。
-
AI Agent 簡介
-
AI Agent 組成部分
-
規劃(Planning)
-
記憶(Memory)
-
工具使用(Tool Use)
-
-
規劃(Planning)
-
任務分解(Self-Reflection)
-
自我反省(Self-Reflection)
-
-
記憶(Memory)
-
記憶類型
-
最大內積搜索(MIPS)
-
-
工具使用(Tool Use)
AI Agent 簡介
所謂 AI Agent,就是一個以 LLM 為核心控制器的一個代理系統。業界開源的項目如 AutoGPT、GPT-Engineer 和 BabyAGI 等,都是類似的例子。
LLM 的潛力不僅僅是生成寫得很好的副本、故事、散文和程序;它可以被框架為一個強大的一般問題解決者。
也就是説,AI Agent 本質是一個控制 LLM 來解決問題的代理系統。LLM 的核心能力是意圖理解與文本生成,如果能讓 LLM 學會使用工具,那麼 LLM 本身的能力也將大大拓展。AI Agent 系統就是這樣一種解決方案。
以 AutoGPT 為例,一個經典的案例是對大模型輸入一個問題:找出一個投資機會。正常情況下,一個 LLM 是無法給出具體的操作的。
而 AutoGPT 的思路,是首先告訴 LLM,這個問題 LLM 一般可以咋解決這個問題,給出幾個選擇,然後 LLM 會挑選一個方法,可能是瀏覽雅虎財經,也可能是閲讀某個文件,然後 AutoGPT 本身就可以根據選擇的結果繼續執行,這種執行可能是用谷歌搜索,也可能直接訪問某個文件,但這些都是 LLM 無法做到的。
AutoGPT 完成這些任務之後繼續帶上之前的記錄發給 LLM,繼續詢問新的解決方案。這就是一個簡單的 AI Agent 的案例。
AI Agent 組成部分
所謂 AI Agent,就是一個以 LLM 為核心控制器的一個代理系統。業界開源的項目如 AutoGPT、GPT-Engineer 和 BabyAGI 等,都是類似的例子。
那麼,為了完成上述能力,實際上一個 AI Agent 系統需要包含幾個主要的部分。Lilian Weng 認為一個 AI Agent 系統應當包含如下圖所示的幾個部分:
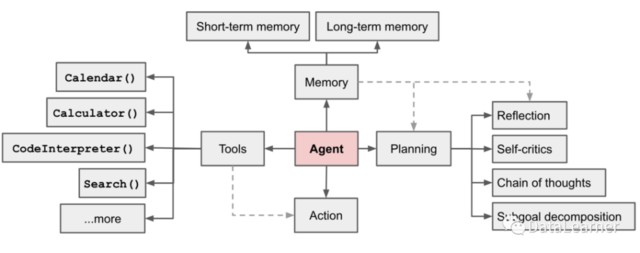
1、規劃(Planning)
子目標和分解:代理將大型任務分解為更小、易於管理的子目標,從而實現複雜任務的高效處理。
反思和提煉:代理可以對過去的行為進行自我批評和自我反思,從錯誤中吸取教訓,併為未來的步驟改進它們,從而提高最終結果的質量。
2、記憶(Memory)
短期記憶:所有的上下文學習,都是利用模型的短期記憶來學習。
(參見提示工程:https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/)
長期記憶:這為代理提供了在很長一段時間內保留和調用(無限)信息的能力,通常是通過利用外部矢量存儲和快速檢索。
3、工具使用(Tool Use)
代理學會調用外部 API 以獲取模型權重中缺少的額外信息(在預訓練後通常難以更改),包括當前信息、代碼執行能力、對專有信息源的訪問等。
下面,對每個部分進行詳細的解釋。
規劃 Planning
複雜的任務通常涉及許多步驟。AI Agent 需要知道他們是什麼,並提前計劃。
1、任務分解(Self-Reflection)
任務分解主要是的目的是將複雜的任務分解成簡單的小任務,這樣 LLM 可以更簡單地解決問題。
這裏介紹 2 類方法:
1)思維鏈已成為增強複雜任務模型性能的標準提示技術(Prompt Technology)。大致就是讓模型 “一步一步地思考”,利用更多的測試時間計算將困難任務分解為更小、更簡單的步驟。CoT 將大型任務轉化為多個可管理的任務,並對模型的思維過程進行了闡釋。
2)思想樹(姚等人 2023 年)通過在每一步探索多種推理可能性來擴展 CoT。它首先將問題分解為多個思維步驟,並每一步生成多個思維,創建一個樹結構。搜索過程可以是 BFS(廣度優先搜索)或 DFS(深度優先搜索),每個狀態都由分類器(通過提示)或多數票評估。
2、自我反省(Self-Reflection)
自我反省是一個重要的方面,它允許 AI Agent 通過完善過去的行動決策和糾正以前的錯誤來迭代地改進。它在現實世界中發揮着至關重要的作用,在現實世界中,試錯是不可避免的。
這裏也包含幾種方法:
1)ReAct(姚等人 2023 年)通過將動作空間擴展為特定於任務的離散動作和語言空間的組合,將推理和行為集成在 LLM 中。前者使 LLM 能夠與環境交互(例如使用維基百科搜索 API),而後者則提示 LLM 以自然語言生成推理跟蹤。
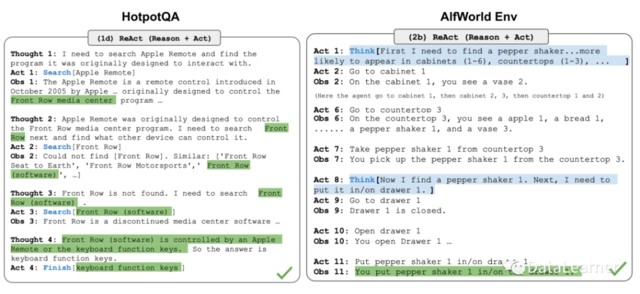
2)Reflexion(Shinn & Labash 2023) 是一個為代理配備動態記憶和自我反思能力以提高推理能力的框架。Reflexion 具有標準的強化學習(Reinforcement Learning,RL)設置,其中獎勵模型提供簡單的二進制獎勵,而行動空間則沿用 ReAct 中的設置,即在特定任務的行動空間中加入語言,以實現複雜的推理步驟。每次行動後,AI Agent 會計算一個啓發式的值,然後根據自我反思的結果決定重置環境以開始新的試驗。
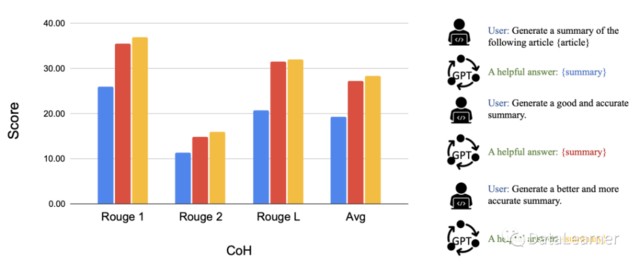
3)Chain of Hindsight(CoH;Liu 等人,2023 年)通過向模型明確展示一系列過去的輸出結果,鼓勵模型改進自己的輸出結果。
記憶 Memory
記憶(Memory),是類似多輪對話中記住之前的輸入和設定的一種能力。在當前的大模型架構中,隨着對話的增長,要記住之前用户的輸入內容再輸出需要消耗大量的硬件資源。大多數模型支持的上下文長度都是非常有限的。
超過這個長度之後,大多數模型的性能都會極具下降或者是不支持。但是長上下文是解決實際問題中必須要面對的。如代碼生成、故事續寫、文本摘要等場景,支撐更長的輸入通常意味着更好的結果。
在這裏,Lili Weng 先是總結了一下人類的記憶分類總結,然後對應到大模型上分別是什麼樣的。
1、記憶類型
記憶可以定義為用於獲取、存儲、保留和檢索信息的過程。人類大腦中有幾種類型的記憶。
感官記憶(Sensory Memory):這是記憶的最早階段,能夠在原始刺激結束後保留對感官信息(視覺、聽覺等)的印象。感官記憶通常只能持續幾秒鐘。其子類別包括圖標記憶(視覺)、回聲記憶(聽覺)和觸覺記憶(觸覺)。
短時記憶(Short-Term Memory,STM)或工作記憶:它存儲我們當前意識到的信息,以及執行學習和推理等複雜認知任務所需的信息。
長時記憶(Long-Term Memory,LTM):長時記憶可以將信息存儲很長時間,從幾天到幾十年不等,存儲容量基本上是無限的。長時記憶有兩種亞型:
-
顯性/陳述性記憶:這是對事實和事件的記憶,指那些可以有意識地回憶起的記憶,包括外顯記憶(事件和經歷)和語義記憶(事實和概念)。 -
內隱/程序性記憶:這種記憶是無意識的,涉及自動執行的技能和例行程序,如騎車或在鍵盤上打字。 
-
感官記憶是類似大模型學習原始輸入(包括文本、圖像或其他模式)的嵌入表徵; -
短時記憶可以理解為大模型的上下文學習,類似於 prompt。由於受到 Transformer 有限上下文窗口長度的限制,它是短暫和有限的,但是可以每次輸入都引入。 -
長期記憶一般就是大模型之外作為外部向量存儲的數據了,AI Agent 可在查詢時加以關注,並可通過快速檢索進行訪問。
工具使用 Tool Use
本文來自硬 AI,原文標題:《AI「未來指南」!OpenAI 安全團隊負責人:AI Agent「詳細教程」》
