
Zhipu AI releases another 'big move', generating videos from any text in 30 seconds

Following text generation and image generation, video generation has also joined the "involution" race.
At the Zhipu Open Day on July 26th, Zhipu AI, which has been frequently active in the large model arena, officially launched the video generation model CogVideoX and unveiled two "big moves":
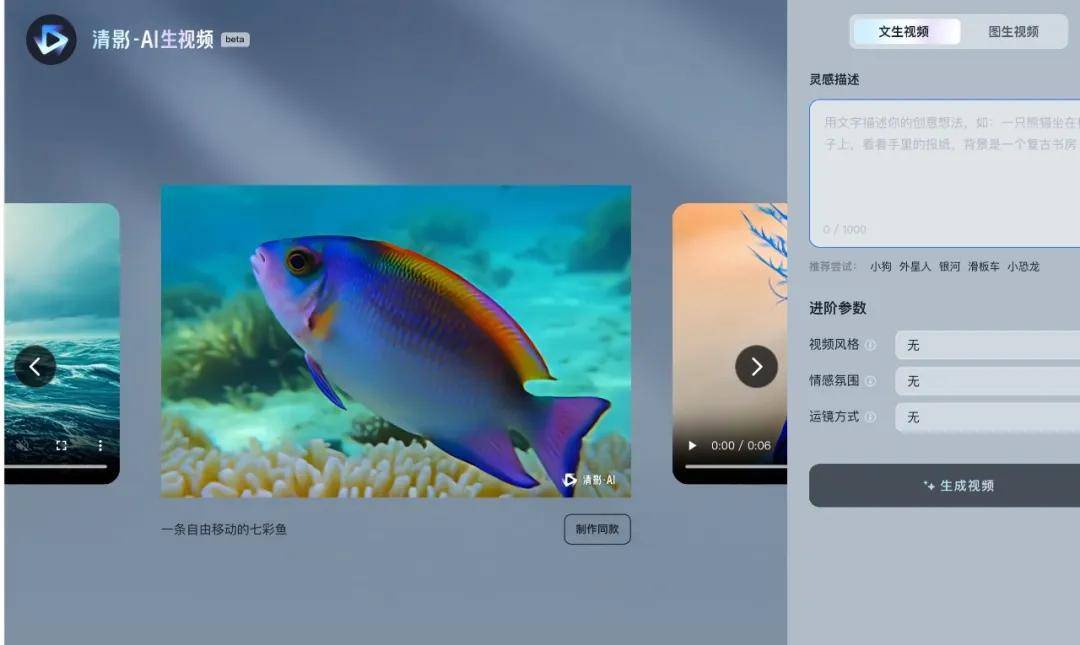
One is Qingying, an intelligent video creation agent developed by Zhipu Qingyan, which can generate high-definition videos with a duration of 6 seconds and a resolution of 1440x960 using text or images.
The other is the "Bring Photos to Life" feature launched on the Zhipu Qingyan mini-program, allowing users to directly upload photos and input prompts to generate dynamic videos.
Unlike products that are only available to a limited audience or require reservations, the Qingying agent is open to all users. By inputting a prompt and selecting a desired style—such as cartoon 3D, black and white, oil painting, cinematic, etc.—and pairing it with the built-in music, users can generate imaginative short videos. Enterprises and developers can also experience text-to-video and image-to-video capabilities by calling APIs.
This raises the question: While video generation products are currently in a "playable" stage, there remains a significant gap before they can be commercialized. What impact will Zhipu AI's entry have?
01 Faster and More Controllable "Qingying"
After Sora ignited the video generation field, the industry experienced a chain reaction. Products like Runway and Pika gained popularity overseas, while domestically, multiple text-to-video large models were unveiled starting in April, with new products launching almost every month.
While the market is becoming increasingly lively, the user experience has fallen into a similar dilemma, with two unavoidable common issues:
First, slow inference speed. Even a 4-second video can take about 10 minutes to generate, and the longer the video, the slower the generation.
Second, poor controllability. Within limited statements and training samples, the results can be decent, but once "boundaries" are crossed, the output can become chaotic.
Some compare it to "gacha" in games, where multiple attempts are needed to get the desired result. However, an undeniable fact is that if text-to-video requires 25 attempts to produce one usable output, with each generation taking at least 10 minutes, obtaining a few seconds of video could cost over four hours of time, making "productivity" a distant dream.
After testing Qingying's text-to-video and image-to-video features in Zhipu Qingyan, we discovered two impressive experiences: generating a 6-second video takes only about 30 seconds, reducing inference time from minutes to seconds; using the "shot language + scene setup + detail description" prompt formula, users generally need only "roll the gacha two or three times" to get satisfactory video content.
For example, in a text-to-video scenario, inputting the prompt "realistic depiction, close-up, a cheetah lying on the ground with its body slightly rising and falling" generated a "deceptively real" video within a minute: the background of grass swaying in the wind, the cheetah's ears twitching, its body rising and falling with each breath, even every whisker appearing lifelike... It could almost be mistaken for a close-up filmed video.
How did Zhipu AI "skip" the pain points common in the industry? Because all technical problems can be solved through technical innovation.
Behind Qingying, Zhipu AI's video creation agent, lies the self-developed video generation model CogVideoX, which adopts the same DiT structure as Sora, integrating text, time, and space.
Through better optimization techniques, CogVideoX's inference speed has improved sixfold compared to its predecessor. To enhance controllability, Zhipu AI developed an end-to-end video understanding model that generates detailed, context-aligned descriptions for vast amounts of video data, strengthening the model's text comprehension and instruction-following capabilities. This ensures the generated videos better match user inputs and can understand ultra-long, complex prompts.
While similar products on the market are still focusing on "usability," Zhipu AI, with its "home run" innovations, has already entered the "user-friendly" stage.
A direct example is the music-matching feature provided by Zhipu Qingyan, which can add music to generated videos—users need only hit publish. Whether for beginners with no video production experience or professional content creators, Qingying can turn imagination into productivity.
02 Scaling Law Validated Again
Behind every seemingly unusual outcome lies inevitability. While competing products are either not publicly available or still in alpha versions, Qingying's emergence as an AI video application accessible to everyone stems from Zhipu AI's years of 深耕 in video generation models.
Rewind to early 2021, nearly two years before ChatGPT's rise, when terms like Transformer and GPT were only discussed in academic circles. Zhipu AI launched the text-to-image model CogView, which could generate images from Chinese text, outperforming OpenAI's Dall·E in MS COCO evaluations. In 2022, CogView2 was released, addressing issues like slow generation speed and low clarity.
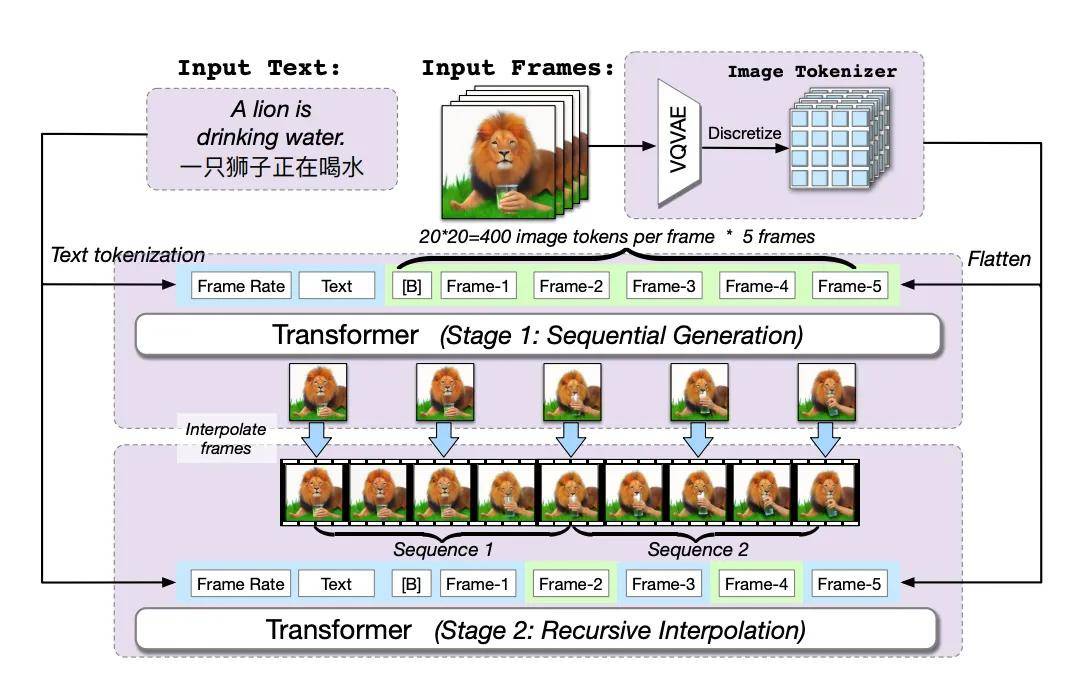
By 2022, Zhipu AI had developed the video generation model CogVideo based on CogView2, capable of generating realistic videos from text.
At the time, the outside world was still immersed in conversational AI, and video generation wasn't a hot topic. But in cutting-edge tech circles, CogVideo was already a "star."
For instance, CogVideo's multi-frame-rate hierarchical training strategy proposed a recursive interpolation method, gradually generating video clips corresponding to each sub-description and interpolating these clips layer by layer to produce the final video. This gave CogVideo the ability to control the intensity of changes during generation, better aligning text and video semantics and enabling efficient text-to-video conversion.
Models like Meta's Make-A-Video, Google's Phenaki and MAGVIT, Microsoft's Nuwa DragNUWA, and NVIDIA's Video LDMs have all referenced CogVideo's strategies, garnering widespread attention on GitHub.
The newly upgraded CogVideoX includes many such innovations. For example, in terms of content coherence, Zhipu AI developed an efficient 3D variational autoencoder (3D VAE) structure, compressing the original video space to 2% of its size. Combined with the 3D RoPE position encoding module, this better captures inter-frame relationships in the time dimension, establishing long-range dependencies in videos.
In other words, the emergence of Qingying is no accident or miracle but the inevitable result of Zhipu AI's incremental innovations.
The large model industry has a famous law called Scaling Law, which states that, barring other constraints, model performance follows a power-law relationship with computational resources, model parameters, and data size. Increasing any of these can improve performance.
According to Zhipu AI, CogVideoX was trained on the Yizhuang high-performance computing cluster, with partners like Huace Film & TV participating in model co-development and bilibili involved in Qingying's R&D. Following this logic, Qingying's 超预期 performance in generation speed and controllability once again validates the Scaling Law.
It’s even foreseeable that, under the Scaling Law, future versions of CogVideoX will achieve higher resolution and longer video generation capabilities.
03 "Multimodality Is the Starting Point of AGI"
One easily overlooked detail is that Zhipu AI did not position Qingying as a standalone product but integrated it as an agent within Zhipu Qingyan.
The reasoning traces back to Zhipu AI CEO Zhang Peng's speech at the ChatGLM launch: "2024 will undoubtedly be the 元年 of AGI, and multimodality is its starting point. To advance toward AGI, staying at the language level isn't enough. We must fuse visual, auditory, and other cognitive modalities around highly abstract cognitive abilities to achieve true AGI."
At ICLR 2024 in May, Zhipu's team reiterated their view on AGI trends: "Text is the foundational key for building large models. The next step is to 混合 train text, images, videos, audio, and other modalities to construct truly native multimodal models."
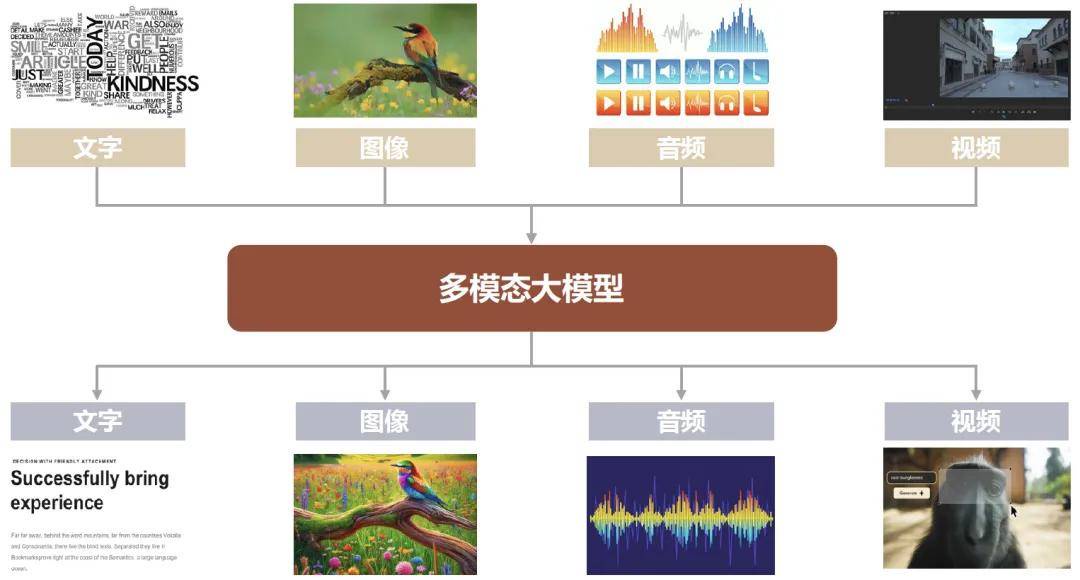
Over the past year, large models have surged in popularity but remain confined as "brains in a vat," with limited applications. For large models to move from theory to practice and create real value in daily life and work, they must develop executive "limbs"—extending beyond language to 听觉 and 视觉 capabilities, seamlessly connecting with the physical world.
Re-examining CogVideoX and Qingying through this lens yields fresh insights.
CogVideoX's text-to-video and image-to-video capabilities can be seen as deconstructing cognitive abilities, first achieving breakthroughs in 单项 skills. Qingying, as an agent, aggregates these capabilities, allowing users to 组合 multiple agents for 高效 problem-solving while native multimodal models are still maturing.
Evidence of this lies in Zhipu AI's model matrix, which includes GLM-4/4V (with 视觉 and agent capabilities), GLM-4-Air (fast 推理, cost-effective), CogView-3 (text-to-image), CharacterGLM (hyper-realistic 角色定制), Embedding-2 (Chinese-optimized vectors), CodeGeeX (coding), GLM-4-9B (open-source), and CogVideoX. Clients can 调用 the optimal model for their needs.
On the consumer side, Zhipu Qingyan already hosts over 300,000 agents, including productivity tools like mind mapping, document assistants, and schedulers. Zhipu AI also launched Qingyan Flow, a multi-agent collaboration system where users can tackle complex tasks through simple natural language instructions.
In summary: While true AGI remains distant, Zhipu AI is bridging the gap through "singular breakthroughs, aggregated capabilities," empowering work, learning, and life with advanced large 模型技术。
04 Closing Thoughts
It's important to acknowledge that current video generation models still have vast room for improvement in understanding physical laws, resolution, motion coherence, and duration.
On the path to AGI, Zhipu AI and other players shouldn't walk alone. As users, we can contribute—whether by generating creative videos on Zhipu Qingyan to showcase AI's potential or leveraging these tools to boost productivity, collectively accelerating multimodal models toward maturity.
The copyright of this article belongs to the original author/organization.
The views expressed herein are solely those of the author and do not reflect the stance of the platform. The content is intended for investment reference purposes only and shall not be considered as investment advice. Please contact us if you have any questions or suggestions regarding the content services provided by the platform.
