
H200 Greenlight: The Breakout Catalyst on NVDA's Path to $6tn?
After weeks of media chatter — from reports of Jensen Huang sparring with White House conservatives to talk that H200 sales to China might still be blocked — Trump ultimately announced that the U.S. Gov. will allow NVIDIA to sell H200 chips to China. Peers will also be permitted to sell chips of comparable H200-class specs into the market.
Blackwell, the newest architecture, and the next-gen Rubin are not on the list. The U.S. Gov. will also take a 25% cut of every sale.
Meanwhile, NVDA has been treading water for a while into Q4, pressured by supply-chain financing constraints, the rise of ASICs, a reset to near-zero in China, and signs of an AI investment bubble. These headwinds capped momentum despite still-strong demand signals elsewhere.
In its recent analysis on AI supply-chain power dynamics, Dolphin Research wrote as follows. See: ‘AI bubble’s original sin: Is NVIDIA the irresistible ‘golden poison pill’ of AI?’
Under a US$4–5trn market-cap burden,$NVIDIA(NVDA.US) must keep shipping chips at scale, propping up half of U.S. equities and selling itself as the ‘black oil’ of the global AI infrastructure era.
One key to that mission is diffusing NVIDIA’s tech across global markets. For example, Trump led GPU vendors to sign deals in the Middle East and elsewhere. When NVDA’s China share fell from ~95% to nearly zero, Jensen Huang warned the U.S. could ‘lose the AI war.’
Six months ago, H20 approvals were hard to get; now Washington is greenlighting H200 and H200-class chips. This raises three questions:
1) What changed over the past six months?
2) Does H200 approval mean a clear runway from here?
3) How much earnings elasticity can NVDA recapture from China?
Let’s dive in.
I. A 180-degree policy turn in half a year — what changed?
When U.S. customers were deploying H200, China was limited to a cut-down H20. As the policy fight escalated, U.S. peers moved on to Blackwell while Chinese buyers could not even get H20; later, even after a U.S. unilateral easing, domestic rules again tightened onshore.
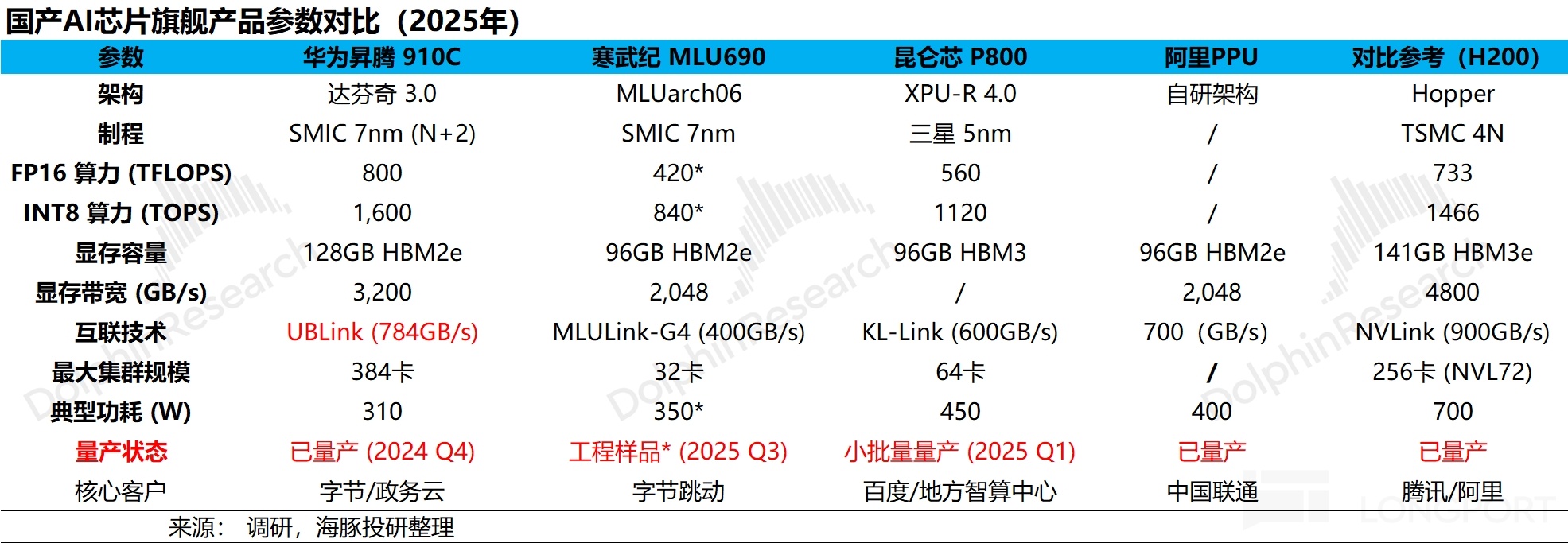
Behind this, H20’s ‘hard’ specs did not clearly beat local rivals if you set aside CUDA and volume supply. On compute, memory, interconnect bandwidth, and cluster capability, it lagged Huawei and others in several areas.
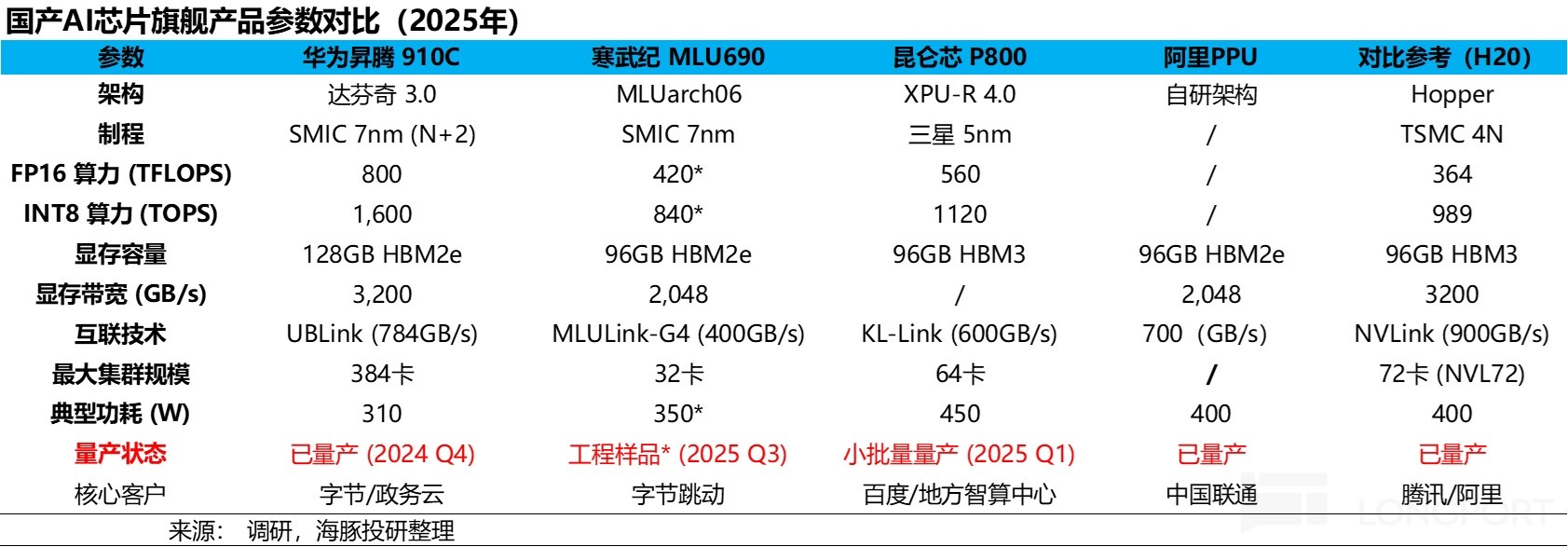
Historically, U.S. controls clamp the high end first; once domestic mass production emerges, previously restricted products are reopened and sold at aggressive prices. This move looks consistent with that playbook, reflecting China’s rapid AI catch-up and a more tactical, progress-based policy stance.
II. H200 — a competitive product in 2026?
While not Blackwell, H200 still delivers roughly 6x H20 performance and is already in service at major overseas CSPs. It remains a frontline part for many large-model workloads.
H200 entered volume production in Q2 2024, so it has been fewer than two years. With most hyperscalers depreciating hardware over 4–6 years, H200 fleets are still in normal use cycles.

Most frontier models today were trained on H100 (H200 mainly upgrades HBM vs. H100). Blackwell has been deployed largely for inference engines and fine-tuning acceleration; the next wave of frontier pretraining is expected to be Blackwell-based.
In other words, even with H200 reopened, there is a generational gap vs. Blackwell for new U.S. frontier training. NVDA typically runs ~2-year product cadences, and Blackwell’s system-level delivery may extend ramp and tuning timelines.
Against current Chinese offerings, H200’s compute advantage remains clear. Aside from Huawei, most domestic players have not solved volume production at comparable performance tiers.
China’s key pain point is still training accelerators, with few truly usable training cards. H200 enables FP8 training supercomputers on par with U.S. performance, helping accelerate frontier model R&D (e.g., GPT-4-class MoE) and industrial apps (e.g., intelligent agents, cloud services).
FP8 is now the mainstream training/inference format, with FP4 still exploratory at a few firms (e.g., OpenAI). H200 lacks native FP4 but can run ‘FP4 storage + FP8 compute’ to narrow the gap vs. Blackwell on FP4 models.
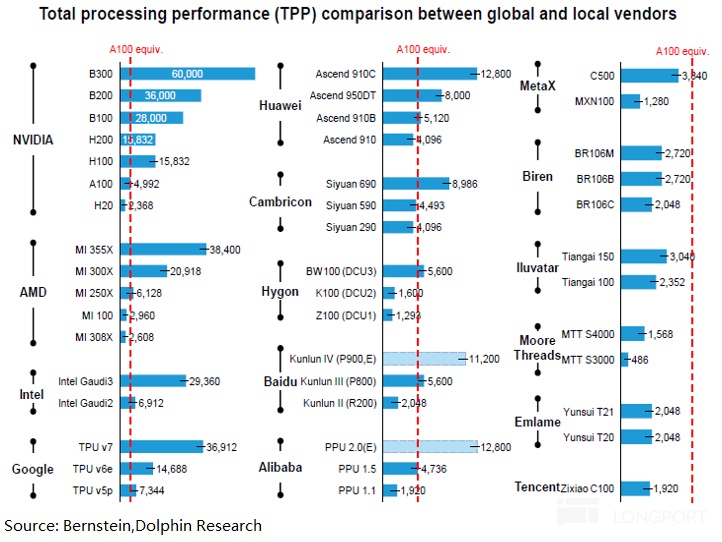
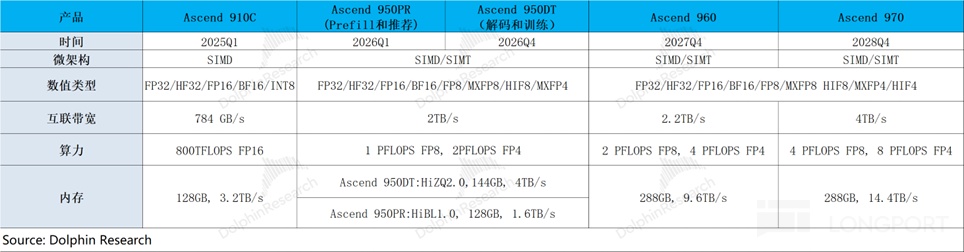
On the domestic roadmap, Huawei’s next-gen 950 (FP8-capable) is expected to be the first strong local training part, with higher memory configs, better card-to-card interconnect, and stronger cluster capability. That would make it a genuine H200 rival.
Even then, matching H200 on total processing performance (TPP) a year later may not be enough; Huawei’s Ascend 960 in Q4 2027 looks more like parity.
Put simply, if Huawei ships on schedule, H200 likely leads domestic AI chips by roughly two years. If the gap were only 6–12 months, H200 might have faced the same cold reception as H20’s brief U.S. easing.
A two-year hardware gap is meaningful when downstream models iterate roughly every six months. As a result, some leading domestic teams reportedly train overseas and bring models back onshore.
III. H200 in China — how long, and for what use cases?
Based on current signals, H200 may have a shipping window of roughly 18–24 months in China. The question is whether NVDA can reclaim its former 95–100% share.
Dolphin Research is skeptical. The structure of demand and policy guardrails have changed.
First, inference workloads are less compute-stringent, and domestic players are highly cost-sensitive given end-user economics. Training workloads, however, still have fewer competitive local options.
Second, to sustain domestic foundry capex and chip R&D, China’s cloud capex plans will reserve sizable shares for the local ecosystem. This is needed to keep the flywheel turning.
Third, AI stacks are iterating fast, and standards themselves become bargaining chips. As seen from H20 to H200, what gets loosened can change with time, reinforcing the push for autonomous compute and full-stack in-house development at Chinese clouds.
Combining these, H200 will likely be tightly targeted for a 1–2 year shipment window and primarily for training in China’s compute deployments. Inference, by choice or necessity, will likely lean on domestic chips.
Practically, sales may adopt a licensing regime, where clouds specify use cases and justify why H200 is indispensable for those scenarios. Approvals would likely focus on training clusters and specific workloads.
IV. Why NVDA still needs China
Even after an enormous profit windfall, NVDA looks anxious into 2026. Growth vectors are narrowing as competitive dynamics shift.
a) China is largely lost: NVDA used to sell H20s into China, but after the ban, China’s contribution fell to ~5% of revenue (from ~20% historically). Given management’s disclosure of roughly US$50mn H20 sales, last quarter’s China revenue was primarily PC and gaming, not AI chips.
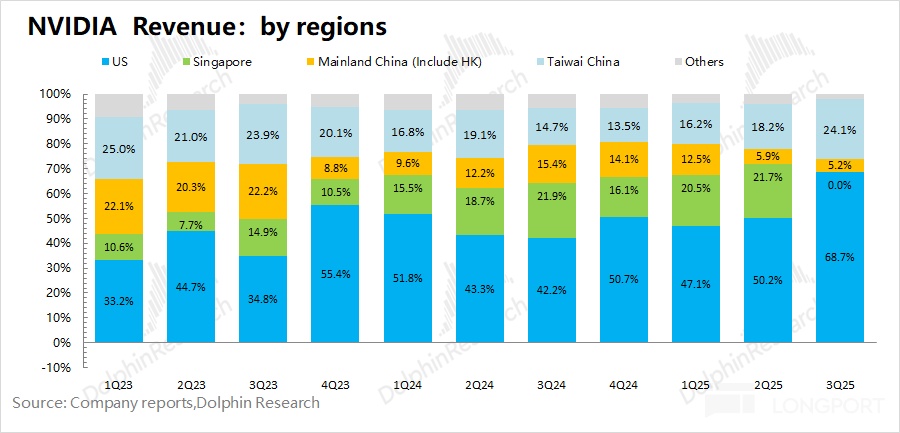
b) The ‘Google Gemini + Broadcom’ threat: Under NVDA’s hefty monopoly rent, hyperscalers like Google and Amazon ramped in-house silicon. With sustained Google TPU orders, Broadcom (AVGO) has become the No. 2 AI silicon player with ~10% share.
At the same time, Gemini and Anthropic models are performing well. The former does not use NVDA at all, and the latter only partially does, showing NVDA is not a mandatory choice for frontier models and spotlighting the ‘Google Gemini + Broadcom’ playbook.
While Google’s TPUs are mainly internal today, markets are hearing Google is in external-supply talks with Meta. If TPUs go external in scale, NVDA’s competitive position would be directly challenged.
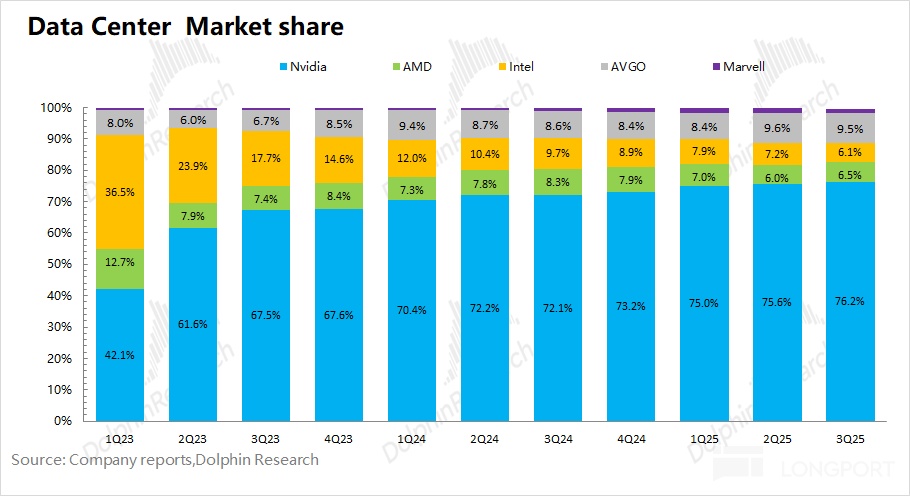
Post-H20 ban, China AI chip revenue is near zero, just as Google TPU threatens NVDA’s margins and order book. NVDA trades at ~22x PE on next FY net income vs. Broadcom’s ~40x, signaling concerns that scarcity fades as the industry pivots to cost-down compute.
Hence, Jensen wants China reopened. Even with a 25% Gov. take on H200 revenue, which drags the segment GPM (assume 65% pre-take becomes ~40% post-take), the upside is still additive vs. guidance. If China also grants import approval, H200 can add near-term revenue quickly.
V. Is China the card that takes NVDA to US$6trn?
Bottom line: reopening adds revenue, but if H200 is ring-fenced into a ‘2-year training gap’ in China, the scale and durability of the uplift will be limited.
Below is Dolphin Research’s view on potential incremental revenue and valuation impact from a China return. The takeaway is clear: this is not NVDA’s US$6trn card.
We group direct China buyers into three buckets: internet majors (ByteDance, Tencent, Alibaba, BIDU), Huawei Cloud, and telcos/enterprise Gov.-cloud (China Mobile, China Unicom, China Telecom, etc.).
a) Internet majors: generally adopt a ‘NVDA/AMD + domestic compute + in-house’ mix and would be the main H200 buyers post-easing. Training is the priority use case.
b) Huawei Cloud: all-in on ‘Huawei compute’ under a self-sufficient model. External accelerators are not the plan.
c) Telcos and Gov.-enterprise clouds: built entirely on domestic compute like Huawei’s, with no overseas accelerators. H200 easing will not trigger purchases here.
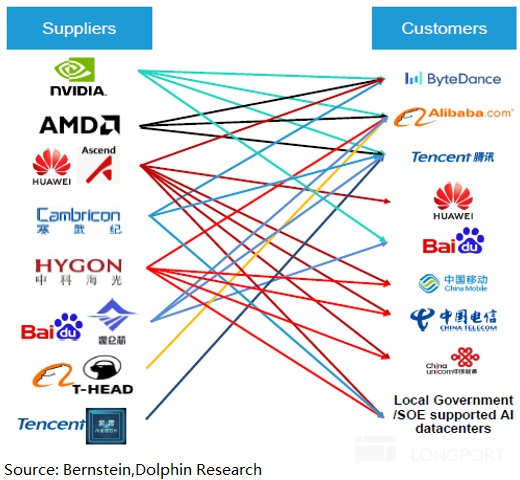
Importantly, the pent-up demand skew is for training, not inference. Among cloud majors (ByteDance, Alibaba, Tencent, BIDU), H200 would be used mainly for training clusters. Inference tokens are already ~35:65 vs. training and trending more toward inference.
That means H200 sales become a share-of-capex question over the next two years. Based on domestic cloud capex plans and market context, Dolphin Research estimates China cloud capex could reach US$123bn in 2026 (+40% YoY).
Roughly 30% of AI capex goes to accelerators, implying a 2025 China AI chip market of about US$38.1bn. NVDA’s 2025 China share could be ~40%, covering most training and some inference.
Given local training chips trail H200, assume NVDA captures 35% share of China’s 2026 AI accelerator spend. That would add about US$13.3bn of incremental revenue to NVDA’s next FY, all incremental to prior guidance.
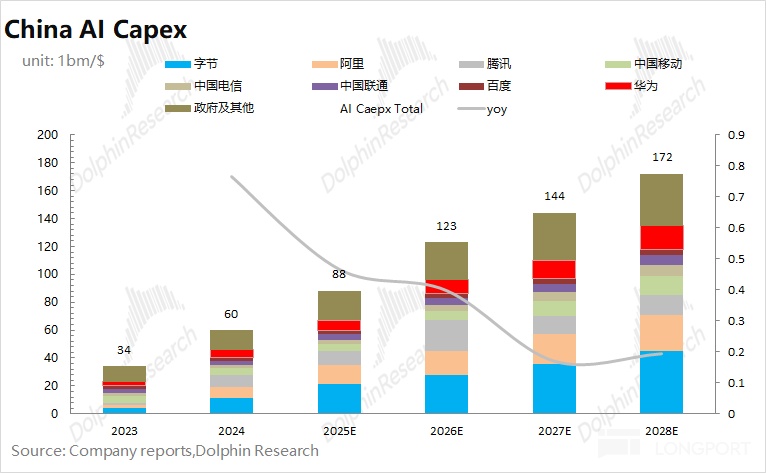
Assuming 65% H200 GPM before the 25% Gov. take, effective GPM would be ~40%. With opex ratio around 10%, US$13.3bn revenue adds only about US$4bn of profit to the next FY.
Ex-China, Dolphin Research estimates FY2027 net income of about US$192.3bn (Rev. +57% YoY, GPM 75%, tax 15.9%). At a US$4.5trn mkt cap, that is ~22x FY2027 PE. Even with China adding ~US$4bn profit (~2% uplift), valuation impact is marginal.
Versus H200 reopening, markets remain more focused on the ‘Google Gemini + Broadcom’ overhang, which weighs on the multiple. If TPUs sell externally at scale, both NVDA’s margins and share could face direct pressure.
Yes, H200 easing helps near-term results, but the impact is small (~2%). The stock’s ~1% move post-news mirrors that. Future export approvals will likely remain a bargaining chip in broader policy dynamics.
Strategically, NVDA should deepen co-development with downstream customers and raise its value-add, better defending against TPUs and other custom ASICs.
<End>
Recent NVDA pieces by Dolphin Research:
Dec 2, 2025, AI infra investing: ‘AI bubble’s original sin: Is NVIDIA the irresistible ‘golden poison pill’ of AI?’
Nov 20, 2025, call trans: NVDA (Trans): Targeting 75% GPM next year; collaboration with OpenAI is not blind
Nov 20, 2025, ER First Take: More important than NFP? Can NVDA save U.S. stocks again?
Oct 29, 2025, GTC Trans: GTC: A flood of shipments next year — is the sky the limit for NVDA?
Risk disclosure and disclaimer: Dolphin Research disclaimer and general disclosures
The copyright of this article belongs to the original author/organization.
The views expressed herein are solely those of the author and do not reflect the stance of the platform. The content is intended for investment reference purposes only and shall not be considered as investment advice. Please contact us if you have any questions or suggestions regarding the content services provided by the platform.
