
NVDA (Trans): Compute Spend Linked to Rev.; Supply Chain Security Prioritized ---
Below is Dolphin Research's transcript of NVIDIA's FY26 Q4 earnings call. For our earnings take, cf. 'NVIDIA: Blowout Results vs. Cool Stock — Has the No.1 Universe Stock Lost Its Shine?'.
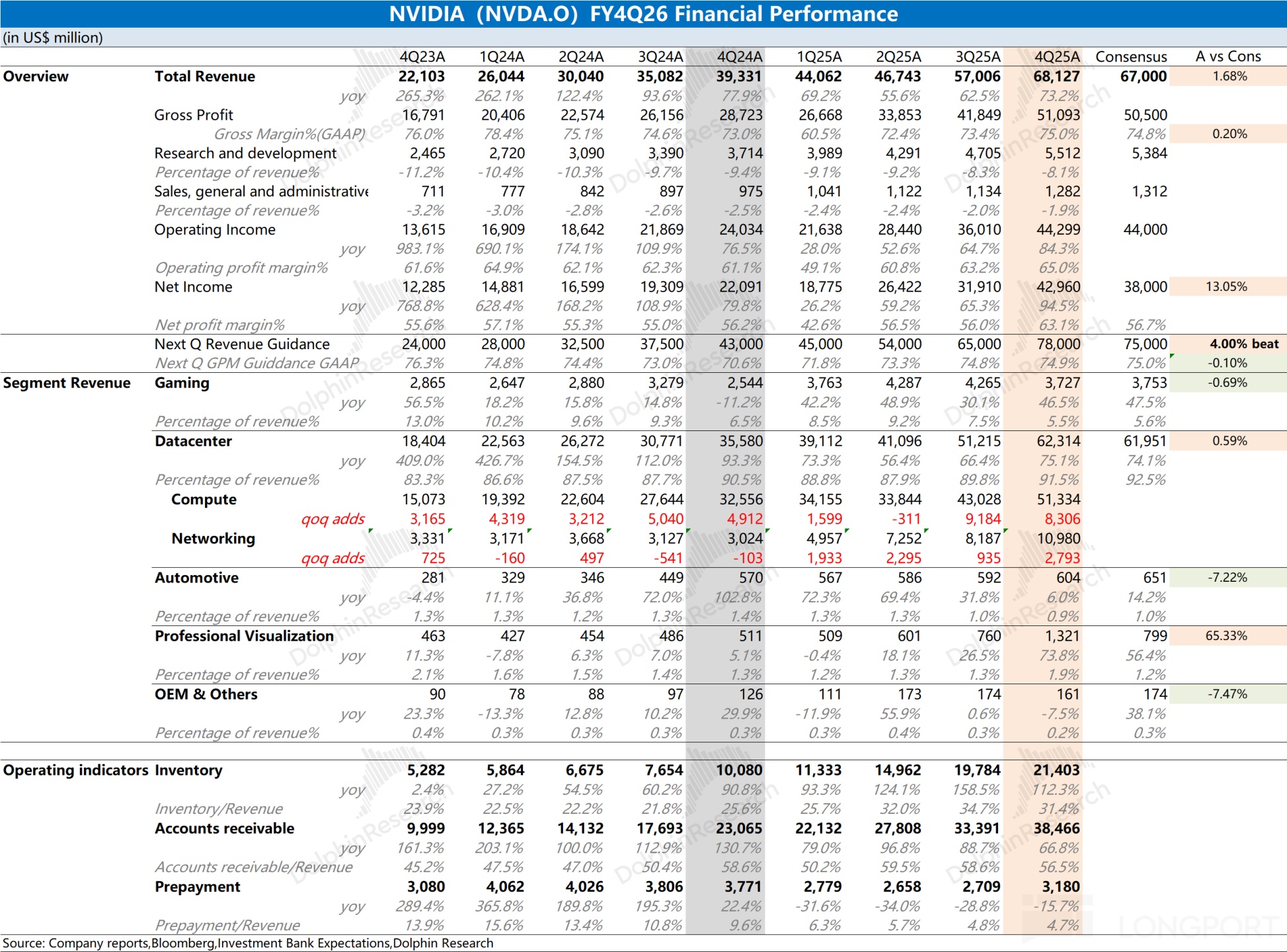
$NVIDIA(NVDA.US) Key takeaways:
1) FY27 guide: full-year Non-GAAP GPM to hold around 75% (mid-70s), consistent with last quarter's commentary. Sustaining margins hinges on delivering cross-generational performance leaps to customers. If perf./watt meaningfully outpaces Moore's Law and perf./$ rises far faster than system cost, high margins are sustainable.
2) Data Center and Rubin: Top five CSPs contribute ~50% of total revenue. Rubin has sampled this week, with mass production in 2H. Its inference cost is 10x lower than Blackwell. Vera is the only data-center CPU supporting LPDDR5, designed for extreme data throughput.
3) China: while H200 received limited approvals, it generated no revenue this quarter. Export licensing remains uncertain, and next-quarter guidance excludes compute revenue from China.
4) View on downstream CapEx: We are at the inflection of Agentic AI — no compute, no tokens; no tokens, no revenue. Compute investment ties directly to revenue growth. Tokens are productive and profitable for customers, which in turn underpins CSP profitability. To generate tokens, customers must secure sufficient capacity, driving a structural shift in CapEx from general-purpose to accelerated computing.
All data centers face strict power budgets (100MW to 1GW). Under power limits, higher perf./watt yields more tokens and more $ revenue. CapEx converts to compute, compute converts to revenue.
5) Memory: Supply likely to be very tight over the next few quarters. If conditions improve by year-end, Gaming could still grow YoY.
6) Space data centers: Unit economics are currently poor, but should improve over time. Space operations follow very different physics vs. ground; despite challenges, certain workloads must be done in orbit. Indeed, Hopper (H100) is already on-orbit. A core use case for space GPUs is ultra-high-res imaging, where in-space inferencing filters valuable signals and discards most raw data to avoid downlink bottlenecks.
7) Strong results, muted stock — buybacks? Protecting the supply chain (strategic investments and ecosystem build-out are top priorities) means NVIDIA will park significant cash across the chain to ensure on-time Blackwell and Rubin shipments. The company continues share repurchases and dividends, and will look for windows to execute buybacks this year.
While results and guidance beat, Jensen had already telegraphed AI shipment targets (Blackwell + Rubin to reach 20 mn units cumulatively by end-2026), so near-term prints matter less. The market focuses more on mid-/long-term outlook and management commentary.
This call offered measured, rather than aggressive, outlook. On GPM concerns, management reiterated that as long as the company delivers high performance, high margins can be sustained. Overall, no more upbeat expectations were provided.
The stock looks undervalued, reflecting worries about ASIC competition and GPM pressure. With revenue growth still robust, even with rising competitive risks, the stock is unlikely to fall below $170 (roughly ~15x PE on FY28 net income).
I. NVIDIA earnings recap
1. FY27 Q1 guide
a. Revenue: $78 bn (+/- 2%), driven by Data Center, with no China compute revenue in the guide. b. GPM: GAAP 74.9% / Non-GAAP 75.0% (±50 bps). c. OPEX: Non-GAAP OPEX ~$7.5 bn; Non-GAAP results include SBC (SBC ~$1.9 bn). d. Supply: Tight supply for advanced architectures to persist; inventory and supply commitments extend into 2027.
2. Full-year outlook:
a. Expect full-year Non-GAAP GPM to hold around 75% (mid-70s). b. OPEX: Non-GAAP OPEX growth approx. 42% YoY (low 40s). c. Tax: FY27 GAAP/Non-GAAP effective tax rate at 17%–19%.
II. Earnings call details
2.1 Management highlights
1. Data Center
a. Performance: Q4 revenue $62 bn (+75% YoY), full-year $194 bn. b. Portfolio: Demand is exceptionally strong; Blackwell Ultra is ramping. CSPs and enterprises have deployed ~9GW of Blackwell infrastructure. - Rubin architecture: includes Vera CPU and Rubin GPU, modular cableless design. Sampled this week, mass production in 2H, with inference cost another 10x lower vs. Blackwell. - Hopper & Ampere: Even prior-gen cloud SKUs are still 'sold out', underscoring extreme compute hunger.
c. Networking: Quarterly revenue $11 bn (3.5x YoY). NVLink 72 is now standard, accounting for two-thirds of Data Center revenue this quarter.
2. Software and model ecosystem
a. The 'Agentic AI' moment has arrived. Deep collaborations with OpenAI (GPT 5.3 Codex) and Meta. b. Invested $10 bn in Anthropic; Anthropic will train/infer on Grace Blackwell and Vera Rubin systems, with Claude Code Work driving enterprise AI adoption. Non-exclusive license with Grok for low-latency inference; drawing on the Mellanox playbook to integrate Grok innovations into the NVIDIA stack.
3. Sovereign AI and regions
a. Sovereign AI: >$30 bn contribution for the year. Canada, France, the UK and others are investing in AI infrastructure in proportion to GDP. b. China: while H200 had limited approvals, no revenue this quarter. Export licensing remains uncertain, and local competitors are rising.
4. Gaming and Pro Visualization
a. Gaming: $3.7 bn (+47% YoY). Blackwell demand is strong, but management flagged supply pressure post-Q1. b. ProViz: first-ever $1 bn+ quarter ($1.3 bn, +159% YoY), driven by AI developers running LLMs on workstations.
5. Auto and Physical AI
Physical AI at scale: FY26 revenue contribution of $6 bn. Autonomous driving: Mercedes CLA to adopt Alpamayo. Robotaxi (Waymo, Tesla, etc.) scaling to drive step-change growth.
2.2 Q&A
Q: You have visibility into FY27 growth, but the market worries cloud CapEx (~$700 bn) is peaking and FCF is tight. What underpins confidence in sustained customer CapEx? If CapEx growth slows, can NVIDIA still grow within current budgets?
A: The logic is straightforward: we are at the inflection of Agentic AI, with surging demand driving massive compute needs. In today's AI world, compute equals revenue. No compute means no tokens, and no tokens means no revenue — compute investment directly ties to revenue growth.
Across code assistants, enterprise AI collaboration platforms (e.g., Claude-related apps), and ISVs building agent systems, enthusiasm is very high. We have hit a tipping point where generated tokens are productive and profitable for customers, reinforcing CSP profitability. Structurally, compute has changed: the $300–400 bn annual traditional software CapEx is shifting to AI. To generate tokens, customers must secure sufficient capacity, translating directly into growth and revenue — a structural shift from general-purpose to accelerated computing.
Q: NVIDIA has made strategic investments in Anthropic, OpenAI, CoreWeave, and even Intel and Nokia. What roles do these play? How do you use the balance sheet to strengthen your ecosystem and participate in its growth?
A: Our core advantage is the ecosystem, which is why our platform is so sought after. Virtually every startup runs on NVIDIA across cloud, on-prem, edge, and robotics, with thousands of AI-native apps built atop our platform. In this new computing era, our goal is for all users and applications to run on NVIDIA.
We start from a strong position as almost everything is built on CUDA. As we expand the AI ecosystem — language AI, physical AI, bioscience, robotics, manufacturing — we want these verticals rooted in NVIDIA. This yields compelling investment opportunities across the stack.
Today's ecosystem is richer than ever. NVIDIA has evolved from a pure GPU computing platform to an AI infrastructure company, spanning compute, AI models, networking, DPU, and more. Each enterprise, industrial, scientific, or robotics domain has its own stack, and our investments are deliberate and strategic: use assets to broaden and deepen NVIDIA ecosystem reach.
Q: Networking accelerated in FY26. Spectrum-X annualized revenue was ~$10 bn in 1H, rising to ~$11–12 bn in 2H. With 102T and Spectrum-X800 coming, what's the trend for Spectrum-X growth into year-end?
A: NVIDIA is now an AI infrastructure company. We architect compute at the rack level, not at the server node level. Within racks, NVLink turns nodes into rack-scale computers, and Spectrum-X plus InfiniBand scale across racks.
NVLink substantially drove Network growth because each rack carries large switch capacity with staggering intra-rack throughput. We may be the world's largest networking company now; despite entering Ethernet switching only a few years ago, we have achieved leadership. Spectrum-X has been a massive success. While we support low-latency, ultra-scale InfiniBand customers, more clients prefer Ethernet-based data centers, so we built Ethernet optimized for AI and showcased its performance on Spectrum-X.
For customers, network performance directly affects ROI. On a $10–20 bn AI factory, even a 10–20% improvement in throughput and efficacy translates into huge revenue deltas. Because our AI infrastructure is so efficient, networking growth remains extremely strong.
Q: Given large context windows and Groq's decoders, will your roadmap focus more on custom silicon for specific workloads or clients? Any strategic shifts with new architectures?
A: Our design principle is to delay crossing interfaces as long as possible. Every die-to-die hop adds latency and power. We do use chiplets/dies, but only when necessary.
In Blackwell and Rubin, we bond two enormous chips at the edge of lithography limits, slashing interface losses common in rival designs and maximizing efficiency. People say our edge is software, but software and architecture are inseparable; our software is fast because our per-FLOP power is optimal at the architecture level.
On Groq and low-latency decoders, I have excellent ideas to share at GTC. The core is the unmatched generality of CUDA. All NVIDIA GPUs are architecturally compatible, so models and stacks tuned for Blackwell also benefit Hopper and even Ampere — why A100 remains vibrant years on.
This compatibility enables massive software engineering investment with confidence that installed GPUs across generations, cloud and on-prem, benefit. It gives customers innovation flexibility and investment protection, translating into superior value-for-money. For targeted competition, we will integrate capabilities like Groq's into the broader NVIDIA architecture, much like expanding via Mellanox, to sustain leadership.
Q: Data Center revenue rose over $10 bn QoQ, with Blackwell as a major accelerator. As Vera Rubin ramps in 2H, should we expect Blackwell-like QoQ growth again?
A: We are focused on a sequential view near term. Over the year, Blackwell sales will run alongside Vera Rubin's launch. Vera Rubin is an excellent architecture with fast deployment, and we have substantial preorders across customers.
It is too early to quantify its initial 2H ramp contribution, but demand and interest are very strong, and we expect virtually every customer to purchase Vera Rubin. Variables are our entry pace and customer deployment speed in data centers.
Q: With Memory tight, can Gaming grow YoY in FY27, or will pressure be significant?
A: We would like to supply more, but due to VRAM and other factors, we expect supply to be very tight over the next few quarters. If supply improves by year-end, Gaming can still grow YoY. It is early to call specifics; we will update as visibility improves.
Q: As AI budgets shift to inference, how does CUDA's importance show?
A: Without CUDA we could not do inference. NVIDIA offers the most efficient inference stack, TensorRT-LLM. To leverage NVLink, we invent new parallel algorithms atop CUDA to distribute inference loads and fully exploit NVLink 72 bandwidth.
With the hard innovations behind NVLink 72 — switches, rack systems, etc. — we achieved generational leaps: 50x perf./watt for inference and 35x better value-for-money. Today, inference equals revenue. As agents proliferate, they collaborate autonomously on tasks like coding and generate exponentially more tokens, often running for hours and producing thousands of monetizable tokens. Faster inference boosts customer monetization.
For CSPs and hyperscalers, tokens per watt caps profitability. All data centers face strict power limits (100MW–1GW), so higher perf./watt yields more tokens and more $ revenue. Every hyperscaler now understands: CapEx converts to compute, compute converts to revenue. Choosing the highest perf./watt architecture is no longer just strategy; it directly determines financial outcomes.
Q: GPM is holding around 75%. With supply visibility into calendar 2027, is this level sustainable? Post-2027, are there memory power/cost innovations to support margins long term?
A: Margin sustainability depends on delivering cross-generational performance leaps. If perf./watt outstrips Moore's Law and perf./$ rises much faster than system costs, high GPM is sustainable.
Global token demand is now fully exponential. Even six-year-old cloud GPUs remain fully utilized with rising rental rates, proving insatiable compute hunger in modern software development. Our strategy is to deliver a complete AI infrastructure every year. This year we launched Blackwell with six new chips; next-gen Vera Rubin and successors will keep multi-chip co-design cadence. Through tight HW/SW co-design, each generation delivers multi-fold perf./watt and value-for-money gains — the core capability underpinning margin durability.
Q: On 'space data centers,' how feasible are they? What are the timelines and economics, and how will they evolve?
A: Economics are currently poor but will improve. Space differs from ground: abundant solar but huge panels; extreme cold but no convection, so heat must radiate via large radiators; liquid cooling is hard due to mass and freezing risks. Despite physics, several workloads must be done in space. NVIDIA GPUs are already in space — Hopper (H100) is on-orbit. A key use is ultra-high-res imaging. Combining optics and AI enables projection, super-resolution, and denoising in real time; sending petabytes of raw data down is costly in bandwidth and latency, so in-space compute filters valuable information. AI in space will yield many attractive applications.
Q: Hyperscalers/CSPs are ~50%, but growth is led by non-hyperscaler customers. Does this mean enterprise, sovereign AI, and model players are growing faster? How do their use cases differ, and will this diversification persist?
A: Top five CSPs contribute ~50%, while the other half is highly diverse — model developers, enterprises, supercomputing centers, and sovereign AI. This segment is growing rapidly. We maintain strong positions with cloud platforms while global customer diversity accelerates, which will benefit us long term.
NVIDIA's advantage is the CUDA-based ecosystem. We are the only accelerated computing platform spanning all clouds, OEM devices, and the edge, and we are cultivating telecom — future wireless is a compute platform and radios will be AI-driven; we built Aerial for that. We also power nearly every robot and autonomous vehicle.
CUDA's flexibility lets one architecture solve language, vision, bio, physics, and other AI/compute problems. Customer diversity is one of our greatest strengths. Without our own ecosystem, programmable processors would still be gated by others' cadences; with CUDA, we expand naturally.
Equally critical are partnerships and platform universality. Whether OpenAI, Anthropic, xAI, Meta, or 1.5 mn open-source models on Hugging Face, all run on NVIDIA. Open source may be the world's second-largest model pool after OpenAI. Our ability to run any model makes the platform general and easy to use, offering safe, future-compatible investments for any nation or enterprise — the key driver of customer diversity.
Q: You are pushing Vera CPU as a standalone product. What role does Vera play in architecture evolution? Is this driven by inference growth or workload heterogeneity? How do you view Vera's prospects as a standalone CPU?
A: At the highest level, our CPU choices differ from others. Vera is the only data-center CPU supporting LPDDR5, tuned for extreme data throughput. We made this choice because the problems we target, especially in AI, are data-driven with record single-thread perf./bandwidth ratios.
Across the AI pipeline — from data preprocessing to pre-training and now post-training — Vera is highly necessary. AI is learning tool use, and many tool environments (simulators or certain logic compute) run purely on CPU or CPU-heavy acceleration. Vera is a superb CPU for the post-training stage.
When algorithmic acceleration saturates, non-accelerable bottlenecks surface, demanding very strong, very fast single-thread CPUs. That was the rationale behind Grace; Vera leaps beyond Grace's performance. We see CPU as critical in the AI pipeline, with Vera as a key coordinator and backbone.
Q: You expect ~$100 bn cash flow this year, and purchase commitments seem past peak. With a strong print but a range-bound stock, this looks like a good buyback window. Why not set a larger buyback, rather than maintain the current plan?
A: We are prudent on capital returns. A top priority is to support the vast AI ecosystem in front of us, from supply chain to app development — ensuring suppliers have capacity and supporting early builders on NVIDIA. Thus, strategic investment and ecosystem build-out remain capital allocation priorities. We continue buybacks and dividends, and will seek windows to execute buybacks this year.
Q: You projected global data center CapEx to reach $3–4 tn by 2030. What drives this? Agents, Physical AI, or other? Do you still have conviction in this multi-trillion TAM?
A: I am very confident. From first principles: future software development will be tokens-driven, and inference is token generation. As noted, innovations like NVLink 72 lift tokens-per-energy 50x. Tokens sit at the core of future compute and software.
Historically, the world spent $300–400 bn annually on traditional compute. Now AI compute demand is 1,000x higher. Previously we 'played back' prewritten code or prerecorded video; today software is generated in real time based on context and intent, requiring far more compute.
We are riding two major waves:
- Agentic AI inflection: In the last 2–3 months, agents exploded. They solve real problems; internally, our engineers use Claude, OpenAI Codex, or Cursor at scale. Companies like Anthropic grew revenue 10x in a year, and their only bottleneck is severely constrained capacity. Token demand is exponential.
- Physical AI follows: next is Physical AI, bringing AI to manufacturing, robotics, and autonomous driving. Autonomy requires massive AI factories to generate tokens for training, and cars must also generate tokens continuously onboard.
This is a new industrial revolution. In this world, compute equals revenue. For CSPs or enterprise software, investing in data centers directly drives revenue growth. If token generation is the future of computing — and I am convinced, with industry consensus — global capacity expansion is far from done. $700 bn per year is just the start; demand goes much further.
<End here>
Risk disclosure and statement:Dolphin Research Disclaimer and General Disclosure
